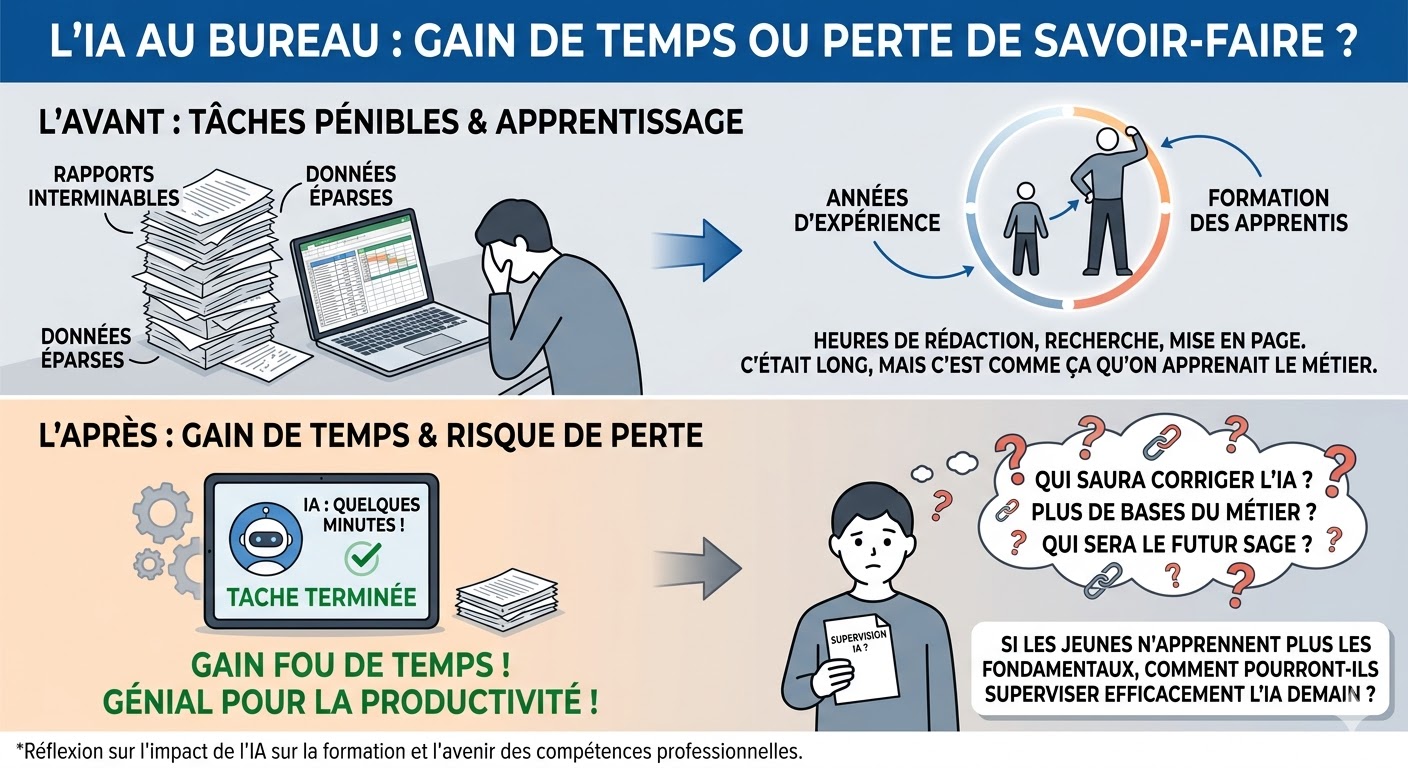
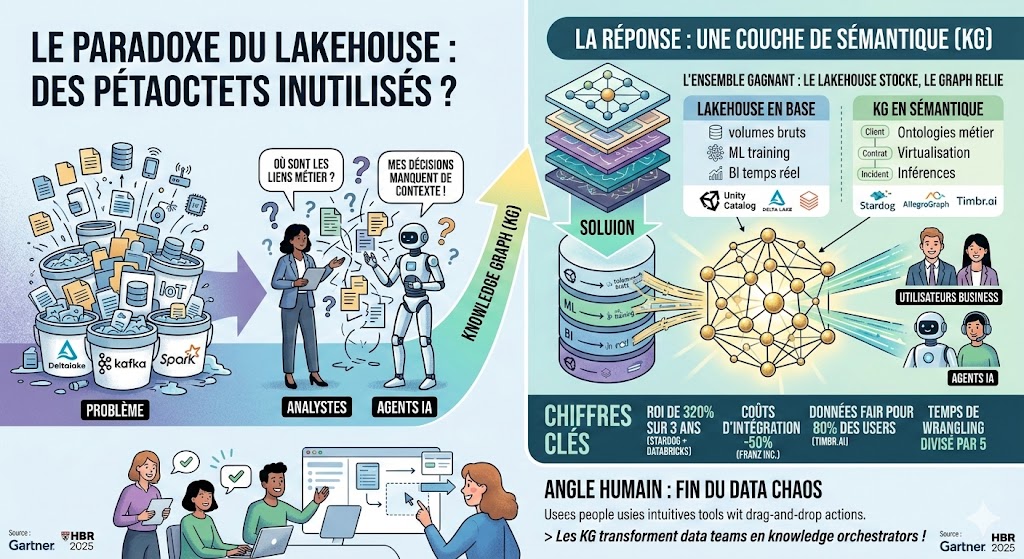
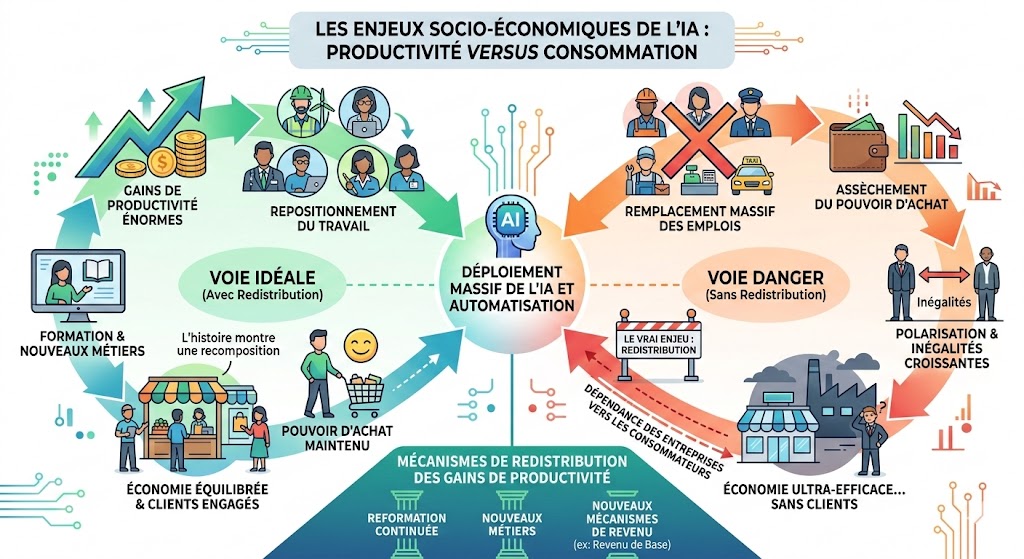
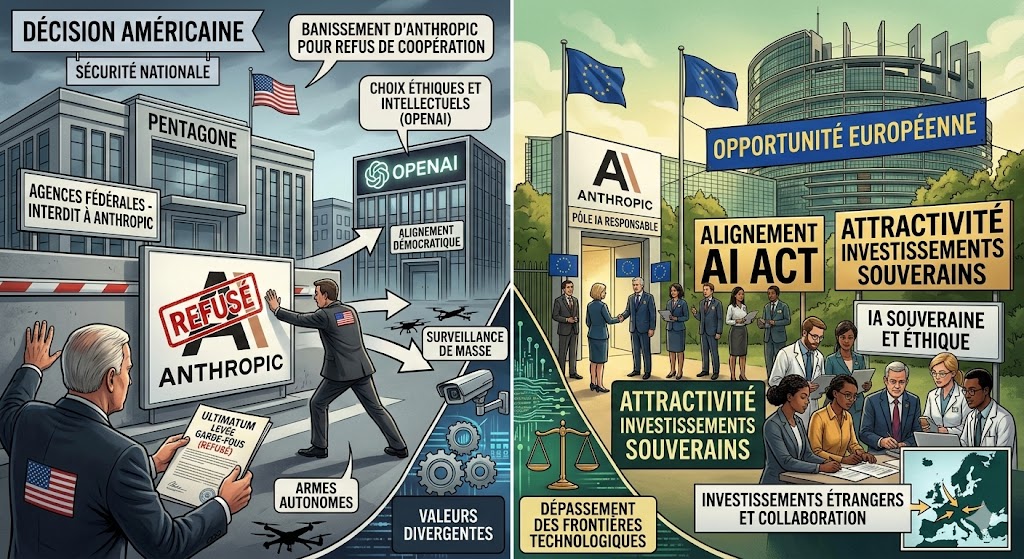
Créativité, IA et école du futur : fini l’usine à disques durs

L’école du futur est une usine à CPU et pas/plus à disques durs ! Le monde change et l’IA avale la connaissance brute. Alors, demain, quelles seront les VRAIE compétences gagnantes … La créativité, la transformation, l’audace ? Dans un monde où les machines excellent à mémoriser et restituer, l’école doit donc s’adapter et former dorénavent des pilotes d’IA, et surtout plus des encyclopédies vivantes. Quid de la créativité ? Il est clair que l’IA recycle brillamment… mais qui est vraiment au comande de cette créativité ? Qui ose le risque ?