

Introduction
Dans cet article nous n’allons pas faire du fine tuning de notre LLM. A la place nous allons utiliser la technique de détection de similarité qui va s’appuyer sur des données extérieures au LLM. D’où le titre de cet article qui indique que nous allons nous lancer progressivement vers le RAG (RAG (Retrieval Augmented Generation). Car c’est finalement ça le RAG: un moyen de mieux contextualiser un LLM avec des données pour lesquelles il n’a pas été entrainé.
Les LLM sont comme nous le savons entrainés sur de vaste jeux de données (Wikipédia et autres), mais voilà dés qu’il s’agit d’être plus spécifique sur une contexte ou un environnement particulier, ils ne sont plus aussi loquace et répondent même parfois n’importe quoi. C’est tout à fait normal car il ne savent naturellement pas tout ! Je vous propose dans cet article d’interroger un LLM sur un contexte particulier, puis nous récupérerons un fichier PDF et verrons comment nous allons pouvoir enrichir ses connaissances.
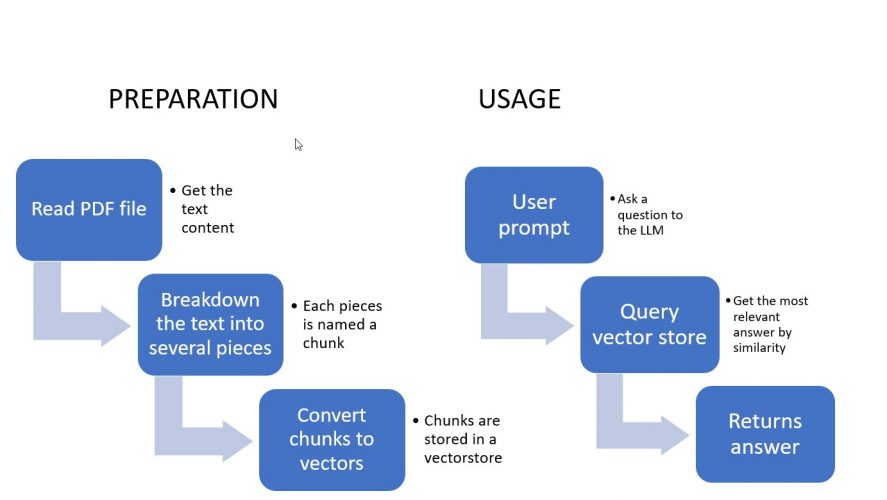
En fait et pour simplifier, ce que nous allons faire, c’est utiliser une base de données vectorielle (FAISS développé par Meta) à part pour stocker notre nouveau contenu dedans. Notre LLM sera utilisé pour comprendre la question et fournir la réponse mais c’est via un calcul de similarité que nous comparerons et retournerons un résultat approprié.
Si ce n’est pas tout à fait clair, je vous propose de voir tout cela en œuvre et ce à partir d’un LLM Open Source FLAN-T5. Volontairement nous n’utiliserons pas GPT pour permettre à tous (et de manière totalement gratuite) de faire ce tutos.
La seule contrainte est d’avoir un compte Hugging Face (lisez cet article pour créer un compte/token) et d’avoir installé Python ou mieux comme moi d’utiliser Google colab. Comme d’habitude tout le code se trouve dans Github.
Objectif
L’objectif est donc d’utiliser le contenu d’un fichier PDF pour modifier la réponse – et donc la contextualiser – de notre LLM. Imaginons que nous interrogions notre LLM (ici en l’occurence FLAN-T5-LARGE) et lui demandions dans combien de films notre cher Benoit Cayla a-t-il joué ? (en anglais: « In how many movies benoit cayla played ? »). Etant donné que je n’ai pas d’homonyme connu dans ce milieu il fort probable que notre LLM réponde 0, n’est-ce pas ?
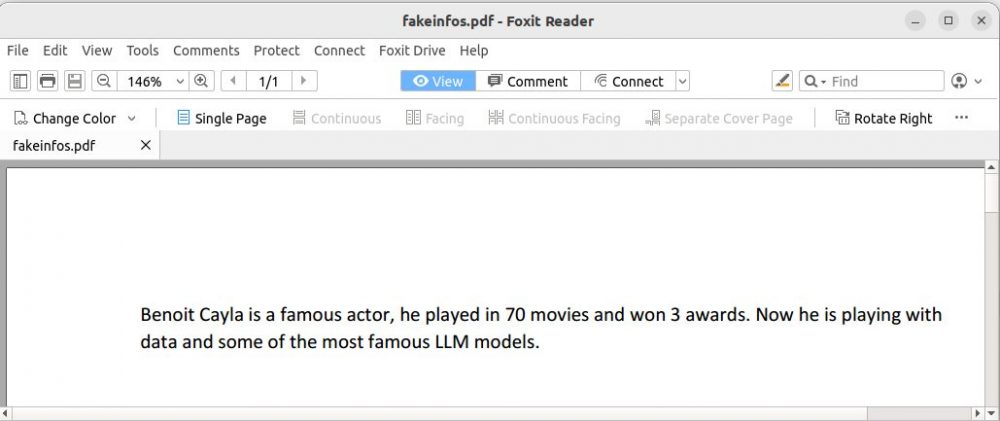
Maintenant imaginons qu’on ajoute des connaissances à notre LLM et que ce dernier récupère des données provenant d’un fichier pdf, comme celui ci dessous:
Notre LLM « influencé » par ce fichier répondra-t-il 70 ?
Voyons voir … Mais voici les étapes que nous allons suivre ensemble:
- Tout d’abord nous allons interroger notre LLM avec cette question et voir sa réponse
- Puis nous importerons notre pdf
- Nous convertirons les données de notre pdf en vecteurs (phase d’embeddings)
- Nous réinterrogerons notre LLM et utiliserons Langchain pour tester la similarité de la question avec les données que nous avons contextualisées.
Initialisations
Avant de commencer, il faut bien sur préparer le terrain. Nous utiliserons Google colab comme précisé en introduction ce qui nous évitera d’installer quoique ce soit sur votre ordinateur. Ensuite nous avons besoin d’installer un certain nombre de packages Python:
!pip install pyPDF2
!pip install faiss-cpu
!pip install sentence_transformers
!pip install huggingface_hubEnsuite il faut vous une clé Hugging Face (cliquez ici si vous voulez voir comment en obtenir une gratuitement), on initialise cette valeur via:
MYHFKEY = "[HF KEY HERE]"
os.environ["HUGGINGFACEHUB_API_TOKEN"] = MYHFKEYEnsuite on importe les packages python:
from PyPDF2 import PdfReader
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.chains.question_answering import load_qa_chain
from langchain import HuggingFaceHub, PromptTemplate, LLMChain
from langchain.embeddings import HuggingFaceEmbeddings
import osVoilà tout est pret pour passer à l’étape suivante et initialiser et interroger notre LLM.
Interroger le LLM
Tout d’abord nous allons interroger notre LLM pour savoir dans combien de films Benoit Cayla a joué.
template = """ {question}"""
prompt_template = PromptTemplate(input_variables=["question"], template=template)
llm=HuggingFaceHub(repo_id="google/flan-t5-large",
model_kwargs={"temperature":1e-10})
chain = LLMChain(llm=llm, prompt=prompt_template)
myQuery = "In how many movies benoit cayla played ?"
chain.run(myQuery)Si vous ne comprenez pas ce code je vous invite à lire l’article suivant. La réponse fournie par le LLM peut par contre surprendre …
127Mince je ne savais pas que j’avais un homonyme acteur … interrogeons encore le LLM et demandons lui ce que ce monsieur fait maintenant:
llm("What Benoit is doing now ?")He is a musicianC’est de plus en plus rigolo ! mais bon ce n’est pas non plus très important … une chose est sure notre LLM croit que Benoit Cayla a joué dans 127 films et qu’il est musicien. Voyons voir ce qu’il en sera quand nous allons rajouter des informations plus à jour avec notre fichier PDF.
Import du fichier PDF
L’import du fichier pdf (qui se trouve dans GitHub) est plutôt simple et s’effectue via la commande wget:
!wget https://raw.githubusercontent.com/datacorner/les-tutos-datacorner.fr/master/datasources/fakeinfos.pdf--2023-11-05 06:55:43-- https://raw.githubusercontent.com/datacorner/les-tutos-datacorner.fr/master/datasources/fakeinfos.pdf
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.109.133, 185.199.110.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 47581 (46K) [application/octet-stream]
Saving to: ‘fakeinfos.pdf’
fakeinfos.pdf 100%[===================>] 46.47K --.-KB/s in 0.01s
2023-11-05 06:55:43 (3.68 MB/s) - ‘fakeinfos.pdf’ saved [47581/47581]Le fichier est maintenant accessible dans notre environnement colab, nous pouvons le lire facilement avec le package pyPDF2:
newdata = PdfReader('/content/fakeinfos.pdf')
allContent = ""
for i, page in enumerate(newdata.pages):
content = page.extract_text()
if content:
allContent += contentNous lisons par ce code toutes les pages du pdf et plaçons le contenu dans la variable texte : allContent. Vérifions son contenu (a quelques espaces près c’est parfaitement exact):
print(allContent)Benoit Cayla is a famou s actor, he played in 70 movies and won 3 awards. Now he is playing with data and some of t he most famous LLM models. Maintenant et comme nos fichiers PDF peuvent être très gros (ce n’est pas le cas ici bien sur) il est mieux de découper notre contenu en plusieurs morceaux (chunks):
text_splitter = CharacterTextSplitter(separator="\n",
chunk_size=200,
chunk_overlap= 20,
length_function= len)
finalAllContent = text_splitter.split_text(allContent)
finalAllContent['Benoit Cayla is a famou s actor, he played in 70 movies and won 3 awards. Now he is playing with \ndata and some of t he most famous LLM models.']Note: Notre tableau/vecteur ci-dessus ne contient qu’un élément.
L’embedding
La phase d’embedding a pour but de convertir nos portions (chunks) de textes en vecteurs numériques qui seront alors utilisables par notre LLM. Pour celà on utilise bien souvent un autre réseau de neurones qui va opérer cette conversion. Dans notre example nous allons utiliser celui de Hugging Face.
embeddings = HuggingFaceEmbeddings()
Import et vectorisation des données du PDF
Il est temps de convertir nos nouvelles informations en vecteurs:
docSearch = FAISS.from_texts(finalAllContent, embeddings) # Meta Faiss vector store
newChain = load_qa_chain(llm, chain_type="stuff")
docs = docSearch.similarity_search(myQuery)Comme précisé en introduction nous n’allons pas altérer notre LLM mais utiliser une recherche par similarité à la place (via la librairie Open Source FAISS de Meta). La recherche de similarité, est une technique utilisée pour trouver des éléments dans un ensemble de données qui sont similaires à une requête donnée. Dans le contexte des LLM, la recherche de similarité implique généralement le calcul de représentations vectorielles du texte, puis la recherche de vecteurs similaires dans un ensemble de données.
On utilise souvent cette approche pour des tâches telles que la recherche d’informations, les systèmes de recommandation et la recommandation de contenu. En fait partout où il est crucial de trouver des éléments similaires par rapport à leur contenu. C’est d’ailleurs le cas ici.
Réinterrogeons notre LLM
newChain.run(input_documents=docs, question=myQuery)70Incroyable n’est-ce pas, cette fois ci il répond correctement (ok, en fonction des informations du PDF). Continuons …
newChain.run(input_documents=docs, question="What Benoit is doing now ?")playing with dataLa preuve est faite, notre LLM est donc réellement influencé par des données externes et répond maintenant en fonction de celle-ci!
Conclusion
Dans cet article nous avons vu beaucoup de choses mais l’objectif était surtout de montrer quen quelques lignes de code il était extrêmement simple d’utiliser nos LLM, de les influencer sans pour autant les altérer et faire du fine-tuning. Les cas d’usages sont bien sur multiples, ce n’est d’ailleurs pas pour rien que j’ai choisi d’utiliser des fichiers PDF 😉
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.