

Introduction
Le document chunking est une pratique courante en intelligence artificielle qui prend de plus en plus d’importance avec la démocratisation des LLM et dutraitements de données textuelles via NLP en général. Son objectif est de permettre le découpage de vastes ensembles de documents en segments plus petits. Cette méthode ou technique facilite grandement l’analyse et le traitement des informations permettant aux algorithmes d’IA d’opérer de manière plus efficiente sur des portions de texte réduites. L’objectif est de réduire la surcharge d’informations et les problèmes de performance liés au traitement de documents entiers. De plus, cette segmentation permet de réduire la complexité des tâches d’analyse, en offrant une approche plus gérable pour les modèles d’IA.
Un des objectifs majeurs du « document chunking » est donc l’amélioration de la précision des résultats. En divisant les documents en unités plus petites, les modèles (notamment nos fameux LLM) peuvent se concentrer sur les informations pertinentes, réduisant ainsi le bruit et permettant une interprétation plus précise des données. Par ailleurs, cette pratique facilite l’apprentissage supervisé en fournissant des segments annotés et étiquetés, favorisant ainsi le développement de modèles plus performants et précis.
Par ailleurs, le « document chunking » contribue à l’optimisation des performances globales des solutions à base d’IA. En traitant les documents par segments, les algorithmes peuvent être parallélisés plus efficacement, ce qui améliore la vitesse de traitement et la capacité à gérer de grands volumes de données. Cette approche s’avère donc particulièrement bénéfique dans les environnements distribués où la performance et l’efficacité sont des enjeux cruciaux.
Pour résumer et faire simple, le « document chunking » constitue un pilier essentiel de l’intelligence artificielle, offrant une méthode efficace pour gérer les données textuelles, réduire la complexité des tâches d’analyse, améliorer la précision des modèles et optimiser les performances des systèmes d’IA dans leur ensemble. C’est aussi une technique indispensable lors de la mise en place de RAG.
Dans cet article on va étudier par la pratique, 3 techniques proposées par langchain:
- Le découpage par texte
- Le découpage sémantique
- Le découpage par token
Préparation
Nous allons utiliser le langage Python et utiliser google colab comme environnement de développement.
Tout d’abordon va installer les librairies python nécessaires (langchain):
!pip install langchain
!pip install --quiet langchain_experimental langchain_openai
!pip install sentence-transformers
!pip install --upgrade --quiet langchain-text-splitters tiktokenEnsuite on va importer directement dans google colab un fichier suffisamment gros, ici on va prendre la déclaration de Joe Biden sur l’état de la nation en 2023. Ce fichier est disponible sur le site huggingface.
!wget https://huggingface.co/datasets/rewoo/sotu_qa_2023/raw/main/state_of_the_union.txtIl ne nous reste plus qu’à importer les librairies nécessaires:
from langchain.text_splitter import CharacterTextSplitter
import matplotlib.pyplot as plt
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddingsLe Caractère chunking
Le Text Chunking proposé par LangChain divise un texte en plusieurs morceaux plus petits et maniables: le texte de base est alors divisé en fonction de caractères spécifiques (ex : sauts de ligne). Cela se révèle particulièrement utile pour traiter de longs textes génériques qui dépassent la capacité de traitement d’un modèle en une seule fois. Mais voila, lors du découpage d’un texte en morceaux distincts, il est possible de perdre du contexte sémantique aux points de division. Gérer un chevauchement (paramètre chunk_overlap) permet de pallier ce problème en conservant une partie du texte précédent dans le morceau suivant. Cela aide le modèle à mieux comprendre la continuité du texte et la relation entre les phrases.
Voyons ce que cela donne en pratique avec notre texte importé précédemment. Ouvrons le fichier texte et découpons le en blocs de 300 caractères, avec un recoupement de 50, le séparateur sera le retour charriot ici.
with open('state_of_the_union.txt') as f:
text = f.read()
text_splitter = CharacterTextSplitter(
separator = "\n\n",
chunk_size = 350,
chunk_overlap = 50,
length_function = len,
is_separator_regex = False)
docs = text_splitter.create_documents([text])Regardons les deux premiers blocs :
print(docs[0].page_content)Following is a transcript of President Biden’s State of the Union address in 2023.
Mr. Speaker. Madam Vice President. Our First Lady and Second Gentleman.
Members of Congress and the Cabinet. Leaders of our military.
Mr. Chief Justice, Associate Justices, and retired Justices of the Supreme Court.
And you, my fellow Americans.print(docs[1].page_content)And you, my fellow Americans.
I start tonight by congratulating the members of the 118th Congress and the new Speaker of the House, Kevin McCarthy.
Mr. Speaker, I look forward to working together.
I also want to congratulate the new leader of the House Democrats and the first Black House Minority Leader in history, Hakeem Jeffries.Ces deux blocs on en effet des lignes communes (étant donné que le séparateur et le retour charriot): ici la dernière ligne du premier bloc et la première du second (« And you, my fellow Americans.« ): c’est bien la notion de recoupement.
On a par ailleurs découpé ce texte en combien de blocs ?
len(docs)150Nous avons donc 150 chunks. Plus intéressant et étant donné que l’on a spécifié un séparateur et une taille, langchain ne va jamais dépasser la taille de bloc demandé (ici 300) et va par contre découper intelligemment en conservant des données cohérentes (via le séparateur). Le résultat est qu’on n’aura pas des blocs ou chunks de même taille, vérifiez vous-même:
for i, item in enumerate(docs):
print(f"Chunk N°{i} -> {len(item.page_content)}")Chunk N°0 -> 332
Chunk N°1 -> 336
Chunk N°2 -> 203
Chunk N°3 -> 297
Chunk N°4 -> 210
...
Chunk N°146 -> 237
Chunk N°147 -> 271
Chunk N°148 -> 295
Chunk N°149 -> 159Regardons graphiquement le résultat:
Y = [ len(y.page_content) for y in docs]
plt.bar(range(len(docs)), Y, color="b")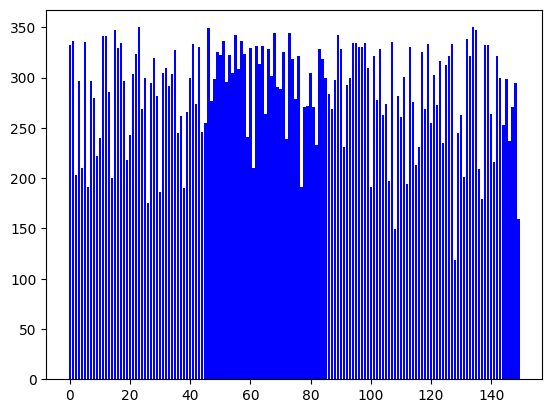
Le Semantic chunk
Si la gestion de chevauchement strict est intéressante, elle n’est pas liée à un contexte ou a la compréhension globale d’un texte. D’où l’idée d’essayer de découper le texte de manière plus intelligente et surtout liée à du sens sémantique. Dit autrement, le chunking sémantique de LangChain vise à diviser un texte en morceaux plus petits et cohérents sur le plan du sens, contrairement aux méthodes de chunking par taille fixe ou par caractère qui se basent uniquement sur la structure du texte.
Voici comment fonctionne le chunking sémantique dans LangChain :
- Segmentation en phrases: Le texte est d’abord divisé en phrases individuelles.
- Regroupement initial: Les phrases sont ensuite regroupées de manière consécutives.
- Représentations vectorielles: Un processus crée des représentations vectorielles pour chaque groupe de phrases. Ces représentations capturent le sens global du groupe sous forme de vecteurs numériques.
- Fusion par similarité: Le « chunker » analyse ensuite la similarité entre les représentations vectorielles des groupes. Si la similarité entre deux groupes dépasse un certain seuil, on les fusionne en un seul chunk sémantique.
- Chunks finaux: Ce processus se poursuit jusqu’à ce qu’il n’y ait plus de groupes de phrases suffisamment similaires à fusionner. Le résultat final est une série de chunks sémantiques, chacun regroupant des phrases étroitement liées sur le plan du sens.
On voit tout de suite que la procédure est plus complexe et mettra aussi plus de temps à traiter. Pour l’embeddings on va utiliser un modèle fournit par Hugging face (sentence-transformers/all-mpnet-base-v2). Ce modèle convertit des phrases et des paragraphes en un espace vectoriel dense de 768 dimensions. Cet espace permettra ensuite d’effectuer les tâches de recherche sémantique nécessaires.
Voyons ce que cela donne (je vais éviter ici d’utiliser des GPUs):
hf_embeddings = HuggingFaceEmbeddings()
model_name = "sentence-transformers/all-mpnet-base-v2"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': False}
hf_embeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
)
text_splitter = SemanticChunker(hf_embeddings)
docs = text_splitter.create_documents([text])Clairement le traitement est beaucoup plus long, ce qui est normal.
len(docs)30On a bien moins de chunks mais par contre ces derniers sont beaucoup plus cohérents. Il est toujours possible de regarder leur contenu via (exemple du premier bloc ci-dessous) :
docs[0].page_contentRegardonc comme précédemment la répartition des chunks par taille:
for i, item in enumerate(docs):
print(f"Chunk N°{i} -> {len(item.page_content)}")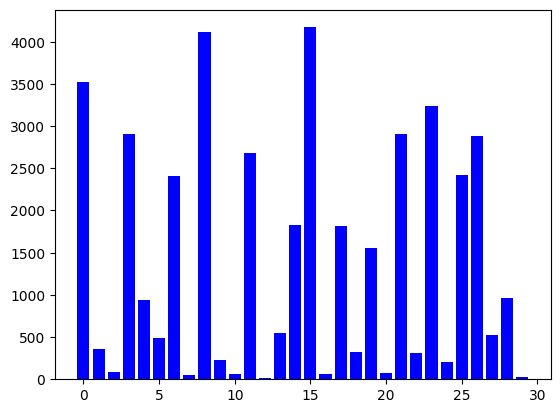
Clairement la répartition n’est pas uniforme, on a des tous petits blocs et des beaucoup plus gros. Aucun problème, car c’est le sens qu’ils portent qui est dorénavant important.
Le Token chunk
Les LLM ont une capacité limitée à traiter un certain nombre de jetons (ou token) à la fois. Pour garantir un fonctionnement optimal, il est important de respecter cette limite. Diviser un gros texte en plusieurs morceaux (chunks) peut aussi s’avérer utile pour contourner cette contrainte. Cependant, il est important de comptabiliser le nombre de jetons présents dans chaque chunk afin de ne pas dépasser la capacité du modèle. OpenAI a proposé une approche de découpage ou de tekenization/BPE (tiktoken) qui est aujourd’hui mis à disposition via langchain.
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1000,
chunk_overlap=100
)
docs = text_splitter.split_text(text)Et coté répartition …
Y = [ len(y) for y in docs]
plt.bar(range(len(docs)), Y, color="b")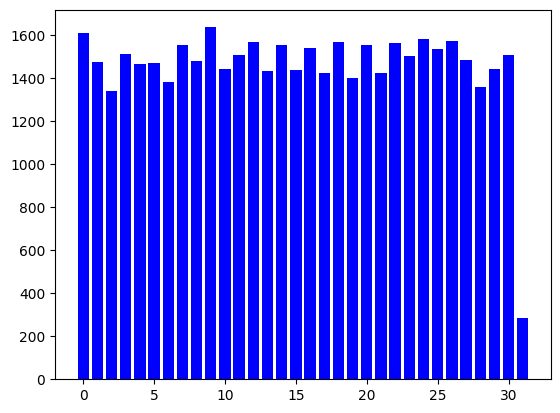
Conclusion
Le document chunking est une technique qui n’en n’est qu’à ces début. Entre un découpage brutal et un découpage sémantique on voit bien qu’un boulevard se dessine entre efficacité opérationnelle, temps de réponse et bien sur précision attendues. Nulle doute donc qu’à ces différentes approches de nouvelles vont très vite s’y ajouter afin de mieux répartir cette balance.
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.