

Introduction
Dans cet article nous allons nous focaliser sur l’une des caractéristiques les plus intéressante (du moins à mon avis) des IA génératives et plus spécifiquement des LLMs: le résumé de texte. Les cas d’utilisations sont en effet incalculables tant cette capacité de synthèse est indispensable dans nombreuse de nos tâches. Les LLMs sont aussi là pour nous faire gagner un temps fou et du coup je me suis dit qu’il était intéressant de voir comment nous pourrions les utiliser pour résumer des portions plus ou moins grandes de textes.
Bien sur je ne vais pas passer en revue tous les LLMs qui possèdent ce genre de capacité, mais en voici quelqu’un qui se démarquent:
- GPT-3 (Generative Pre-trained Transformer 3): Développé par OpenAI, GPT-3 est l’un des modèles les plus avancés en matière de traitement du langage naturel (qui ne connait pas chatGPT aujourd’hui ?).
- BERT (Bidirectional Encoder Representations from Transformers): Bien que BERT soit souvent utilisé pour des tâches telles que la compréhension de texte, il peut également être adapté pour générer des résumés en extrayant les parties les plus importantes d’un texte.
- T5 (Text-to-Text Transfer Transformer): Développé par Google, T5 a été conçu pour traiter toutes les tâches de traitement du langage naturel sous la forme d’une tâche de texte-à-texte. Il peut être utilisé pour résumer du texte.
- BART: Ce modèle de Meta/Facebook AI a été spécialement conçu pour la génération de résumés.
- XLNet: Un autre modèle développé par Google AI, XLNet peut également être utilisé pour générer des résumés en utilisant ses capacités de modélisation du langage.
- Turing-NLG (Natural Language Generation): Développé par OpenAI, Turing-NLG est un modèle de langage avancé qui peut être utilisé pour des tâches de génération de texte, y compris les résumés.
- CTRL (Conditional Transformer Language Model): Développé par Salesforce, CTRL est capable de générer du texte en fonction de divers contextes conditionnels, ce qui le rend utile pour la génération de résumés.
Dans cet article nous allons utiliser BART (facebook/meta) qui d’ailleurs utilise une approche de séquence à séquence pour résumer les corpus de texte. Et comme je me sens d’humeur généreuse aujourd’hui nous allons voir comment effectuer cette fonction de résumé de 4 manières différentes ! Comme d’habitude toutes les sources utilisées dans cet article sont accessible (Cf. lien du cadre ci-dessus).
Initialisations
Tout commence par un texte à résumer … Bien sur j’ai demandé à chatGPT de me raconter une histoire drole et voilà ce qu’il m’a répondu …
Un pingouin décide de partir en vacances. Il fait beau, le soleil brille, et il pense que c'est le moment idéal pour prendre un peu de bon temps. Il réserve un billet pour Hawaï et s'envole joyeusement vers cette destination ensoleillée. Arrivé à Hawaï, le pingouin se rend sur la plage et s'installe confortablement sur sa serviette. Il décide de profiter du soleil et de faire une petite sieste. Alors qu'il est en train de se détendre, il sent quelque chose de mouillé sur son bec. Il ouvre les yeux et découvre qu'un toucan est en train de lui faire de l'ombre avec son énorme bec coloré. Étonné, le pingouin se redresse et dit : Eh bien, qu'est-ce que tu fais ici ? Les toucans ne vivent pas à Hawaï !
Le toucan répond avec un sourire : Eh bien, mon ami, moi aussi, je suis en vacances ! Le pingouin rit et accepte la compagnie du toucan. Les deux amis passent la journée à siroter des cocktails, à danser sur la plage, et à profiter de la belle île.
Le lendemain, le pingouin décide de rentrer chez lui. Il remercie le toucan pour la belle journée et prend un vol de retour vers sa banquise.
Quand il arrive chez lui, ses amis pingouins le regardent avec étonnement. Où étais-tu ? demandent-ils. Le pingouin sourit et répond : J'étais à Hawaï, et j'ai même rencontré un toucan en vacances là-bas !
Ses amis le regardent incrédules et lui demandent : Un toucan à Hawaï ? C'est une blague, non ?
Le pingouin rit et dit : Eh bien, parfois, il faut un peu de fantaisie pour rendre la vie plus amusante ! Et c'est ainsi que le pingouin raconta à ses amis la plus étrange, mais aussi la plus drôle, des aventures de vacances à Hawaï avec un toucan exotique.Qu’à cela ne tienne nous allons voir comment faire un résumé de cette histoire (de 1657 caractères). Comme précisé précédemment nous allons aborder 4 méthodes pour utiliser BART:
- Méthode 1: Avec Hugging Face et Python
- Méthode 2: Avec Hugging Face et les APIs
- Méthode 3: Avec Hugging Face et les pipeline API
- Méthode 4: Localement en téléchargement le modèle BART
Pour ce tuto, nous allons utiliser un notebook colab afin que se soit accessible pour tous (sans compter que BART est Open Source et libre d’accès). Vous n’aurez donc rien à payer pour essayer ce modèle. On va commencer par initialiser la variable qui contient la clé hugging Face (pour voir comment la récupérer, lisez cet article).
MYHFKEY = "[PUT YOUR HUGGING FACE HERE"
headers = {"Authorization": "Bearer " + MYHFKEY}Nous devons ensuite installer les packages Python nécessaires pour ce tuto:
!pip install langchain
!pip install huggingface_hub
!pip install transformers
!pip install fairseqEnsuite quelques imports Python:
import os
from langchain import PromptTemplate, HuggingFaceHub, LLMChain
import warnings
import requests
warnings.filterwarnings('ignore')Ensuite nous initialisons notre variable qui va contenir le texte :
frText = "Un pingouin décide de partir en vacances ..."Il est a noter ici que BART a été entrainé sur des données Anglaise, néanmoins grâce à ses capacités de traductions nous allons voir comment il gère le Français.
Méthode 1: Utilisation via Python
Dans l’article qui introduisait l’utilisation des LLM nous avons déjà vu comment configurer et utiliser un LLM en utilisant Hugging Face, je ne vais donc pas détailler le code ci-dessous. On notera juste la référence au repo_id (facebook/bart-large-cnn) qui va permettre à Hugging Face d’utiliser ce LLM.
template = """ {text}"""
prompt_template = PromptTemplate(input_variables=["text"], template=template)
llm=HuggingFaceHub(repo_id="facebook/bart-large-cnn")
chain = LLMChain(llm=llm, prompt=prompt_template)
exceprt = chain.run(frText)
print(exceprt)Un pingouin réserve un billet pour Hawaï et s'envole joyeusement vers cette destination ensoleillée. Il ouvre les yeux et découvre qu'un toucan est en train de lui faire de l'ombre avec son énorme bec coloré.Honnêtement le résultat n’est pas si mal … le texte résumé fait 208 caractères, nous avons donc une réduction de 12% environ.
Méthode 2: Utilisation des APIs Hugging Face
Dans l’interface Hugging Face de BART, il est possible de récupérer un snipet de code permettant l’utilisation des APIs en quelques lignes.
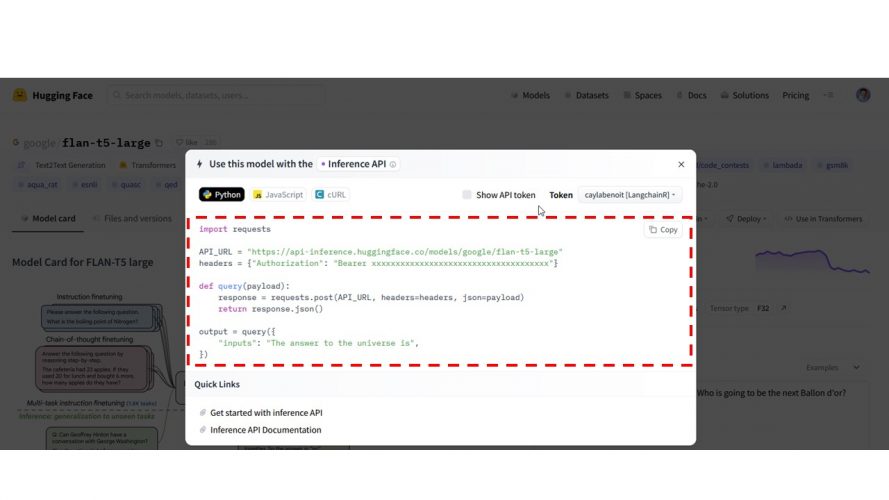
Il n’y a qu’à copier le code et l’utiliser. A noter que ce code est aussi disponible en Javascript !
import requests
API_URL = "https://api-inference.huggingface.co/models/facebook/bart-large-cnn"
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query({
"inputs": frText,
})
print(output)[{'summary_text': "Un pingouin réserve un billet pour Hawaï et s'envole joyeusement vers cette destination ensoleillée. Il ouvre les yeux et découvre qu'un toucan est en train de lui faire de l'ombre avec son énorme bec coloré. Les deux amis passent la journée à siroter des cocktails."}]On notera que que résultat est rendu dans un JSON. Rien de plus simple donc pour regarder la taille du texte rendu:
len(output[0]['summary_text'])Cette fois ci nous avons 266 caractères mais le ratio reste à peu de choses près le même.
Méthode 3: Utiliser l’API transformers
On peut aussi utiliser l’API transformers fournie par Hugging Face
from transformers import pipeline
summarizer = pipeline("summarization",
model="facebook/bart-large-cnn")
response = summarizer(frText, max_length=200, min_length=30, do_sample=False)
print(response)[{'summary_text': "Un pingouin réserve un billet pour Hawaï et s'envole joyeusement vers cette destination ensoleillée. Il ouvre les yeux et découvre qu'un toucan est en train de lui faire de l'ombre avec son énorme bec coloré. Les deux amis passent la journée à siroter des cocktails."}]Méthode 4: Exécution locale
Cette méthode est encore plus intéressante car elle ouvre la porte au fine-tuning de BART. En effet nous allons ici télécharger le modèle BART localement (enfin dans dans cas de figure nous allons le télécharger dans colab), puis nous utiliserons directement le modèle. Pour plus d’exemple mais aussi aller plus loin, n’hésitez pas à regarder le Github.
Commençons par télécharger le modèle (ça peut prendre du temps car il pèse plus de 3,5 Go) ! et comme il est compressé, et bien il faudra le décompresser ensuite. Dans Google colab, tapez:
!wget https://dl.fbaipublicfiles.com/fairseq/models/bart.large.tar.gz
!tar -xzvf bart.large.tar.gzNote: j’ai téléchargé la version « large » du modèle pour avoir de bons résultats, mais il existe d’autres versions dont la version de base qui est plus légère: Regardez ici pour plus d’information.
Maintenant nous allons utiliser la librairie fairseq fournie par facebook/meta pour utiliser BART.
from fairseq.models.bart import BARTModel
bart = BARTModel.from_pretrained('bart.large', checkpoint_file='model.pt')
hypotheses_batch = bart.sample([frText],
beam=4,
lenpen=2.0,
max_len_b=140,
min_len=55,
no_repeat_ngram_size=3)
print(hypotheses_batch)Il est possible que vous attendiez un certain temps avant de voir apparaitre le résultat …
1042301B [00:00, 3984083.86B/s]
456318B [00:00, 9743208.61B/s]
["Un pingouin décide de partir en vacances. Il réserve un billet pour Hawaï et s'envole joyeusement vers cette destination ensoleillée. Arrivé à Hawaï, le pingouin se rend sur la plage et s'installe confortablement sur sa serviette. Il fait beau, le soleil brille, et il pense que c'est le moment idéal pour prendre un peu de bon temps. Il décide de profiter du soleil et de faire une petite sieste. Le lendemain, le"]Conclusion
Dans cet article nous avons vu comment utiliser le LLM BART dans l’objectif de faire un résumé de texte. Nous avons vu quatre différentes techniques, l’objectif étant aussi de montrer qu’il y a plusieurs manière techniques d’utiliser ces LLM: c’est ce qui en fait leur richesse mais aussi leur complexité. La dernière méthode est particulièrement pertinente car elle nous ouvre la porte à l’optimisation contextuelle (ou fine-tuning) de ce modèle. Mais ça sera l’objet d’un autre article …
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.