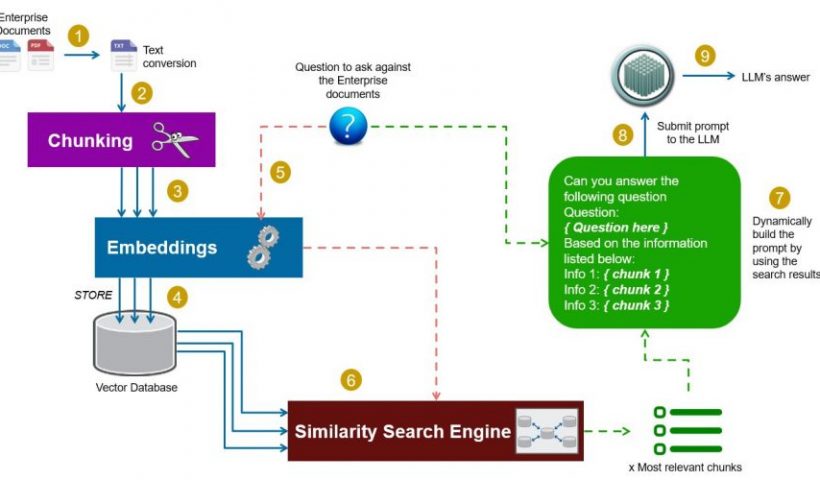
Suite à l’un de mes précédent article sur le RAG (Retrieval Augmented Generation), et quelques commentaires pertinents de lecteurs, je me dois d’aller plus dans le détail sur cette technologie. En fait je vais faire mieux que cela, et je vais décomposer pierre par pierre cette technique et vous montrer qu’elle n’est pas très complexe finalement.
Commençons par un article explicatif, et les prochain seront eux focalisés sur la mise en oeuvre étape par étape.