

Vous êtes à la recherche d’un outil de visualisation de données et malheureusement vous ne pouvez pas investir dans un Tableau ou autre QlikView powerBI ? Vous n’êtes pas « technique » ou du moins vous désirez créer des Data Viz ou des dashboard sans avoir à manipuler du code (enfin un peu de SQL quand même) ? Si vous correspondez à ce profil je vous propose de regarder de plus près Apache Superset … et pour vous épargner les efforts dus à l’installation et aux premiers pas dans cette solution, je vous propose de vous aider à mettre le pied à l’étrier.
Alors, suivez le guide 🙂
Introduction
Qu’est-ce que Apache Superset ?
Si on se réfère au site web de la solution:
Apache Superset est une application moderne Web de Business Intelligence qui adaptée aux entreprises.Superset est rapide, léger, intuitif et doté d’options qui permettent aux utilisateurs de toutes compétences d’explorer et de visualiser facilement leurs données, des simples diagrammes circulaires aux graphiques géospatiaux très détaillés.
Traduction du site: https://superset.apache.org/docs/intro
Superset est donc bel et bien un outil de Data Viz. Mais surtout Superset est un outil Open Source (sous license Apache-2.0 license) ce qui signifie que l’on peut l’utiliser librement et même modifier le code pour l’adapter à des besoins particuliers, sympa non ?
Etant personnellement un grand fan de Tableau j’ai voulu tester cet outil pour voir ce qu’il avait dans le ventre et si il pouvait répondre à des besoins assez simple. Évidemment je ne m’attend pas à trouver un pur concurrent de Tableau, mais disons que si il pouvait répondre à 80% des besoins de Data Viz (Cf. loi de Pareto) et bien, je me dis que ça serait déjà un pari gagné !
Commençons par l’installation …
Installation
C’est un outil Open Source, donc bien évidemment je me dis que l’installation risque d’être un peu ardue. Malheureusement, je n’ai pas tout à fait tord car quand je me suis lancé dans l’installation je dois avouer avoir eu quelques soucis ! la documentation n’était pas toujours d’une grande aide, mais heureusement la communauté étant plutôt active, j’ai pu trouver la solution à chacun de mes problèmes.
Voici donc le déroulement de mon installation sur Linux Ubuntu 22.
Avant de commencer, vous pouvez aller vous balader sur les deux sites suivant:
- Github: https://github.com/apache/superset
- Superset : https://superset.apache.org/docs/installation/
Pour ce post, on va partir d’une installation from scratch (soyons fou) (https://superset.apache.org/docs/installation/installing-superset-from-scratch)
Tout d’abord et c’est évident, vous devez avoir installé Python (en effet superset est codé en Python !). Ensuite, selon votre OS vous devez vous assurer que certaines librairies systèmes sont bien installées: la page ici recense d’ailleurs les commandes à lancer.
Installation des packages
De mon coté avec ubuntu 22, j’ai lancé:
$ sudo apt-get install build-essential libssl-dev libffi-dev python3-dev python3-pip libsasl2-dev libldap2-dev default-libmysqlclient-dev
Comme c’est mentionné sur le site, il est ensuite vivement recommandé d’utiliser un environnement virtuel python. Cela évite ultérieurement une grosse pagaille avec les librairies Python …
Créons cet environnement virtuel dans un répertoire particulier que j’ai créé pour superset. Je créé ensuite l’environnement virtuel dans ce répertoire (.venv_Superset):
$ mkdir superset $ cd superset $ python3 -m venv .venv_Superset
J’active ensuite l’environnement virtuel:
$ . .venv_Superset/bin/activate
Le prompt doit avoir changé, indiquant que vous utilisé maintenant cet environnement virtuel (vierge), voici le résultat dans ma console:
(.venv_Superset) benoit@benoit-laptop:~/superset$
Nous avons un environnement Python qui est donc vierge, on peut maintenant procéder à l’installation. Néanmoins si vous suivez la documentation telle quelle, certains packages Python seront manquants et l’installation n’ira pas bien loin. Avant toute chose je vous recommande d’installer manuellement au préalable les paquets suivants:
$ pip install sqlparse=='0.4.3' $ pip install marshmallow-enum
Puis vous pourrez installer superset:
pip install apache-superset
Configuration
Une fois les packages installés il faut créer un fichier de configuration (superset_config.py) qui sera lancé avec superset et qui permet de lui préciser ses paramètres de fonctionnement. Un template est proposé sur le site de superset ici.
Le mieux est en effet de partir de ce template, puis de modifier les clés secretes (SECRET_KEY, SUPERSET_SECRET_KEY et aussi MAPBOX_API_KEY).
Astuce: Si vous comptez utiliser une source de données de type sqlite, ajoutez la ligne suivante dans le fichier de configuration:
PREVENT_UNSAFE_DB_CONNECTIONS = False
Note: si vous installez superset sur windows il faut alors créer les variables d’environnement suivantes: FLASK_APP et SUPERSET_SECRET_KEY
Finalisation de l’installation
Normalement, tout est maintenant prêt, lancez les commandes (indiquées dans la documentation) dans l’ordre:
$ export FLASK_APP=superset # initialize the database $ superset db upgrade # Create an admin user in your metadata database (use `admin` as username to be able to load the examples) $ superset fab create-admin # Load some data to play with $ superset load_examples # Create default roles and permissions $ superset init
La commande « superset fab create-admin » vous permet de créer l’utilisateur admin (user/password), gardez bien de coté les valeurs que vous précisez 😉
Note: Dans la documentation il est mentionné de lancer aussi les commandes suivantes:
# Build javascript assets $ cd superset-frontend $ npm ci $ npm run build $ cd ..
Malheureusement, le répertoire « superset-frontend » n’étant pas créé auparavant, ces commandes sont donc inutiles (sans doute un héritage d’une ancienne version …).
Maintenant vous devez pouvoir lancer le server (web):
$ superset run -p 8088 --with-threads --reload --debugger
Ouvrez votre navigateur à l’adresse http://localhost:8088 pour voir le résultat:
Un tour rapide ?
Ajouter une référence à une base de données
Bien sur nous pourrions utiliser les données exemples fournies, mais ça serait trop simple n’est-ce pas ? Je vous propose donc de partir de zéro. Pour cela nous devons commencer par référencer une base de données. pour cet article j’utiliserai une base SQLite qui contient quelques tables.
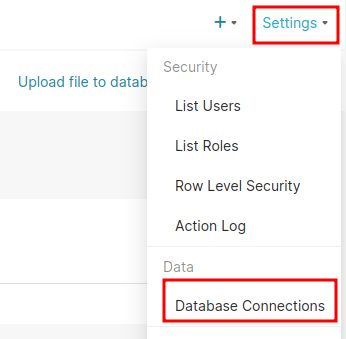
Pour cela allez dans le coin en haut a droite et sélectionnez Settings, puis Database Connections :
Ensuite dans l’écran suivant toujours en haut à droite cliquez sur le bouton [+ Database]:
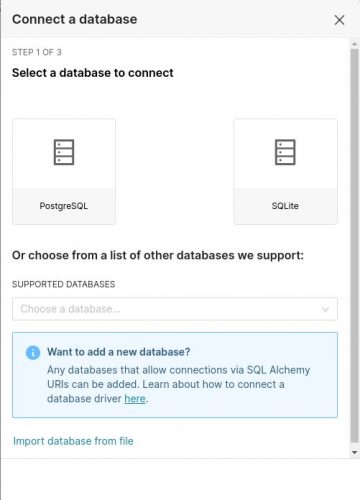
Nous allons bien sur choisir SQLLite mais sachez que Superset propose pas mal de connecteurs (en gros ceux que supporte SQLAlchemy), vous pouvez consulter la liste ici.
Maintenant Superset vous demande juste deux informations:
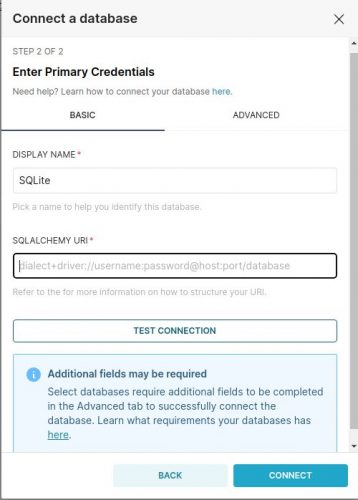
La première est bien sur le nom que vous allez donner à votre source de données (mettez le nom de votre choix). La seconde est l’URI qui va vous permettre la connectivité à la source elle même. La syntaxe de cet URI est propre au type de source de données et bien sur aux parametres de connectivités. Dans le cas de SQLite c’est assez simple puisqu’il ne nous faut que le chelin vers le fichier (sqlite:////home//benoit//superset//dbsample.sqlite).
Il y a même un bouton qui permet de tester si la connexion fonctionne 🙂
Validez en cliquant sur Connect pour créer la source de données.
Création d’un Dataset
Un Dataset (comme son nom l’indique) vous permet de choisir un ensemble de données. Cet ensemble peut être une simple table ou le résultat d’une requête SQL.
- A partir d’une table: c’est très simple il suffit de cliquer sur l’onglet Dataset en haut à gauche puis de sélectionner la source de données, puis la table que l’on veut référencer comme source de données :
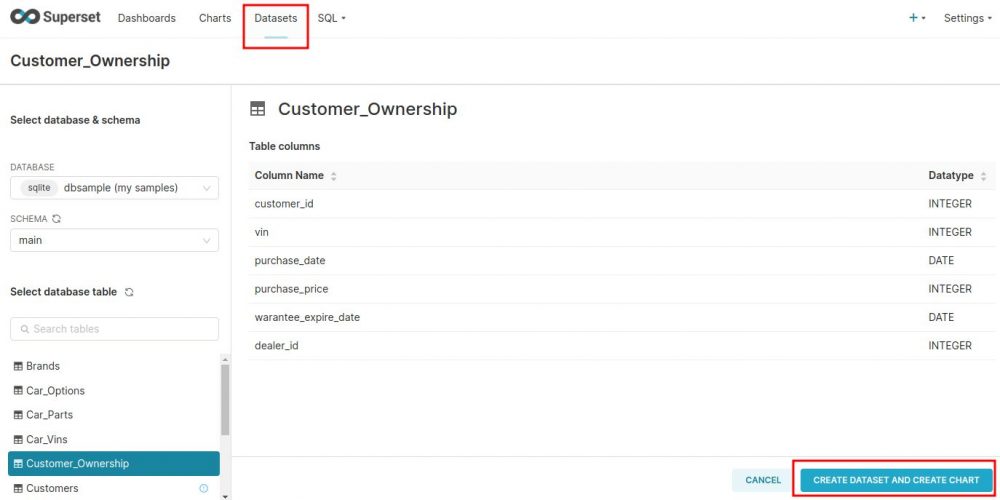
- A partir d’une requête SQL: Il faut sélectionner l’assistant de requête SQL (SQL Lab) comme ci-dessous. Ensuite on selectionne les table dont on a besoin pour la requête sur le panneau de gauche puis on construit la requête sur le panneau en haut à droite. il est même possible de voir le résultat et de l’ajuster. une fois que la requête est satisfaisante (ici je récupère par exemple sur 2 tables les prix de voitures payés par sexe), il suffit de sauvegarder le Dataset en cliquant sur SAVE:
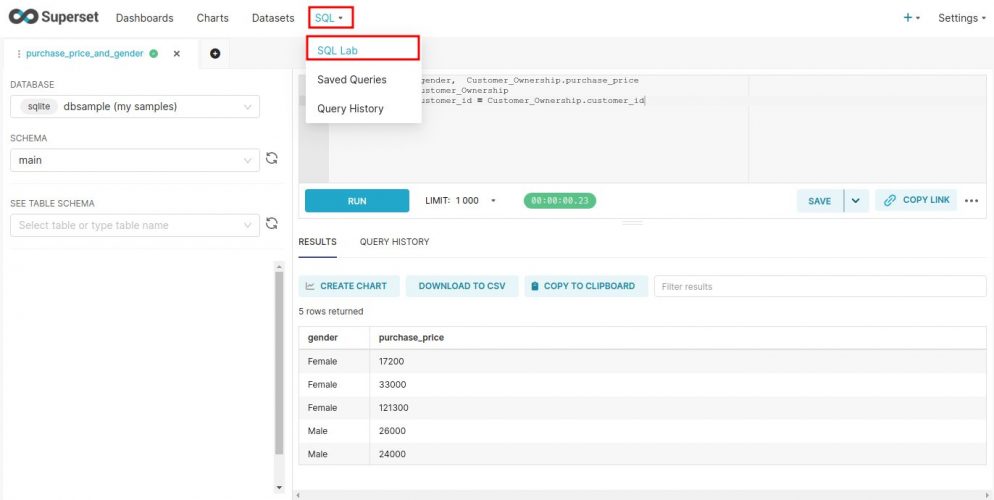
Préparation du Dataset
Comme avec Tableau et d’autres outils d’analytiques. par défaut Superset travaille avec des dimensions et metriques. En gros les dimensions sont les axes d’analyse tandis que les metriques permettent de voir les résultats d’aggrégats par dimensions.
Superset considère donc en résumé:
- Les « metrics »: qui sont les résultats d’aggregats
- Les « dimensions »: qui sont les axes d’analyses et de reporting
Le premier travail va consister à définir pour chaque colonne de notre Dataset si c’est une dimension ou si la valeur de notre colonne va être utilisé pour un calcul d’agrégat (donc une metrique). Pour celà on retourne dans la liste des Datasets et on sélectionne le Dataset que l’on vient de créer.
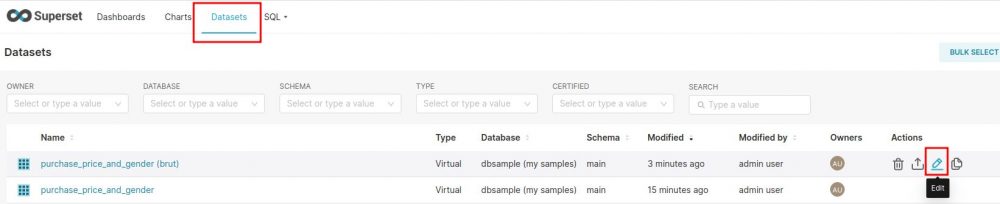
Attention: ne cliquez pas sur le Dataset mais sur le crayon à droite pour le modifier.
Une fenetre popup s’ouvre permettant de configurer notre Dataset et le préparer pour une analyse ultérieure. Etrangement, il n’y a aucune colonne par défaut ! pas de soucis, cliquez sur l’onglet column et synchronisez en cliquant sur le bouton « SYNC COLUMNS FROM SOURCE » :
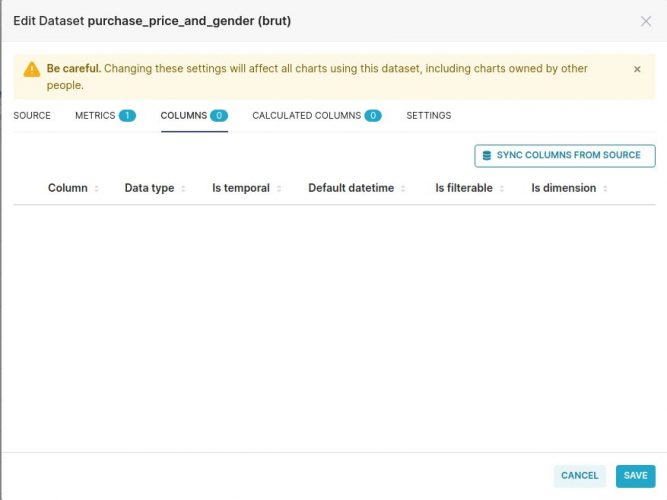
La liste des colonnes (ici seulement deux) doit être rafraichie selon le dataset comme suit :
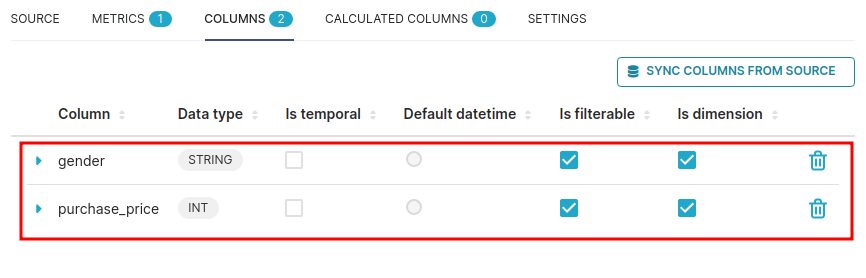
Nous devons modifier plusieurs choses:
- La colonne « purchase_price » est un prix/montant, ce n’est donc pas par nature un axe d’analyse. On va le retirer des dimensions possible en déselectionnant la mention « Is Dimension ». En fait on va même supprimer cette colonne de l’onglet COLUMNS !
- Dans l’onglet METRICS on va créer un nouvel agrégât qui calculera automatiquement la somme des montants. Pour celà on va ajouter une metric, et lui affecter la valeur sum(purchase_price) :
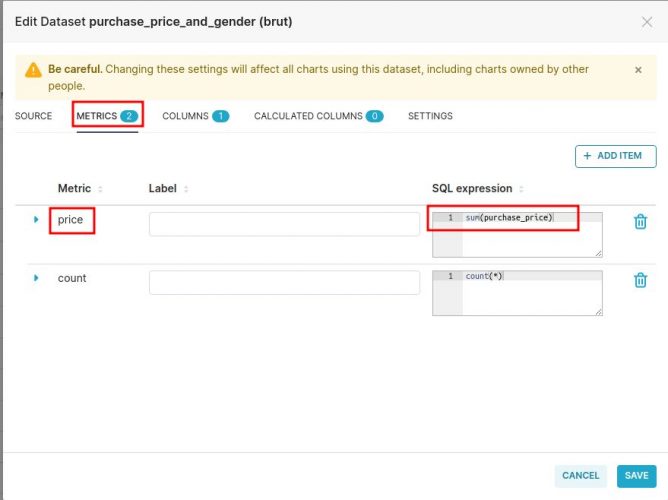
Voilà notre Dataset et maintenant prêt à l’emploi !
Notre premier graphe
Nous avons créé un Dataset très simple avec une variable catégorielle (le sexe/gender qui est ici la seule dimension) et une valeur d’agrégât (metric). Nous allons donc logiquement créer un diagramme en barre avec la somme des montants payés par sexe !
Cliquons sur l’onglet Charts en haut à gauche, puis sur le bouton « + CHART ».
Nous devons choisir deux choses:
- Le Dataset qui est la source de données de notre graphe, nous allons bien sur sélectionner celui que nous venons de créer
- Le type de graphe. Ici nous sélectionnerons un « Bar Chart »
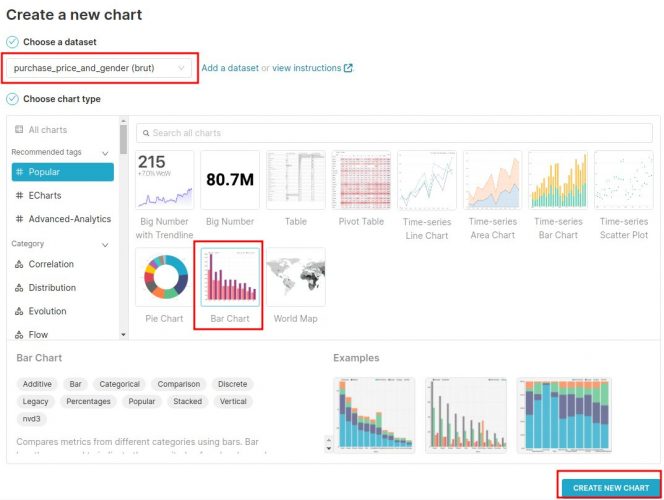
Cliquez ensuite sur CREATE NEW CHART pour ouvrir l’outil de création de graphe:
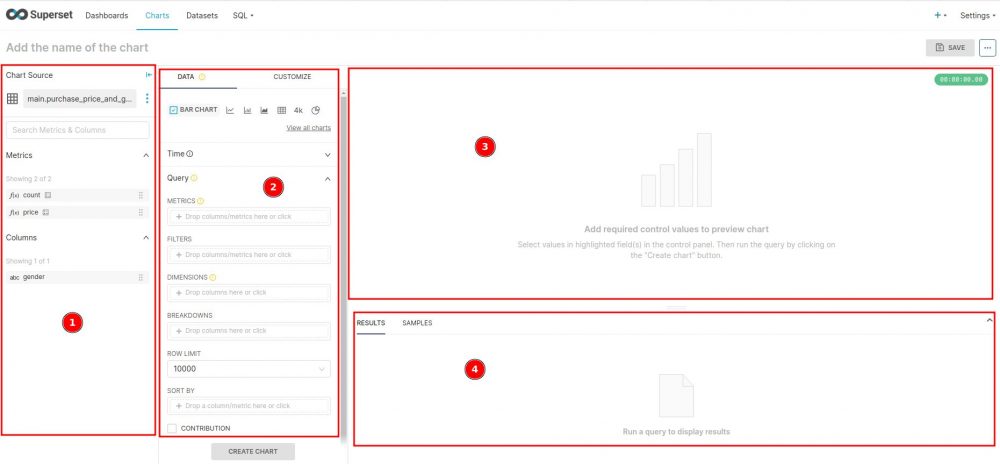
Cet écran se divise en 4 parties:
- La sélection de la source de données (notre dataset) ainsi que les dimensions (colonnes) et aggrégats (metrics) disponibles.
- L’utilisation et la disposition des dimensions/agrégâts
- Le rendu grahique
- Le résultat en mode tabulaire
Créons notre diagramme en baton avec pour dimension: gender et pour metric: price. Pour celà il suffit de déplacer les valeurs de la zone 1 vers la zone 2. Cliquez sur CREATE CHART:
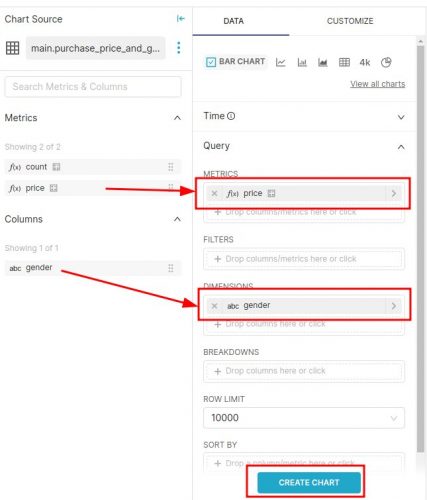
Et voila le résultat :
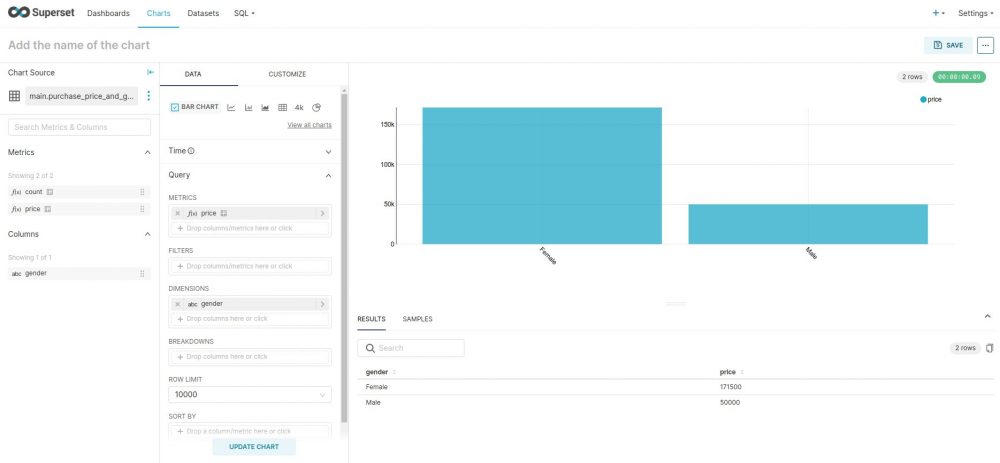
Conclusion
En quelques minutes nous avons créé un premier graphe, certes simple mais sans taper une ligne de code, ce qui est plutôt plaisant, non ? C’est d’autant plus satisfaisant que Superset est un outil gratuit et Open Source …
Le seul bémol reste l’installation qui peut s’avérer fastidieuse (attention notament avec les conflits de packages Python) ! mais nous sommes dans le monde de l’Open Source, c’est donc quelque part le prix à payer.
En ce qui me concerne je trouve que ce projet est extrêmement prometteur. il a l’avantage d’avoir une forte communauté et s’avère être aujourd’hui l’une des meilleure alternative gratuite et Open Source aux géants de la Data Viz ! De plus le nombre de bases de données qu’il supporte est assez impressionnant. Je ne l’ai pas couvert dans cet article (peut être un prochain qui sait 😉 ) mais les capacités de Dashboarding sont aussi prometteuses …
En bref, un outil sérieux mais qui nécessite quand même des connaissances SQL pour pouvoir être efficace (à quand un outil de design graphique SQL ?). Je m’interroge aussi sur sa capacité à supporter de la charge (clustering, load balancing, etc.)
A suivre donc, dans l’attente je continue à l’utiliser pour les explorations 😉
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.
Excellente introduction à Apache Superset.
Je n’ai pas rencontré les mêmes difficultés que vous lors de l’installation mais je m’attends à en rencontrer concernant la connectivité aux BDD.
L’intêret de cet outil de dataviz, selon moi, réside dans sa capacité à concilier base de données traditionnelles (MySQL, Orable…) et données temps réels (Spark, Hive…).
A tester donc!