IA multi-agents : la fin des IA solitaires ?
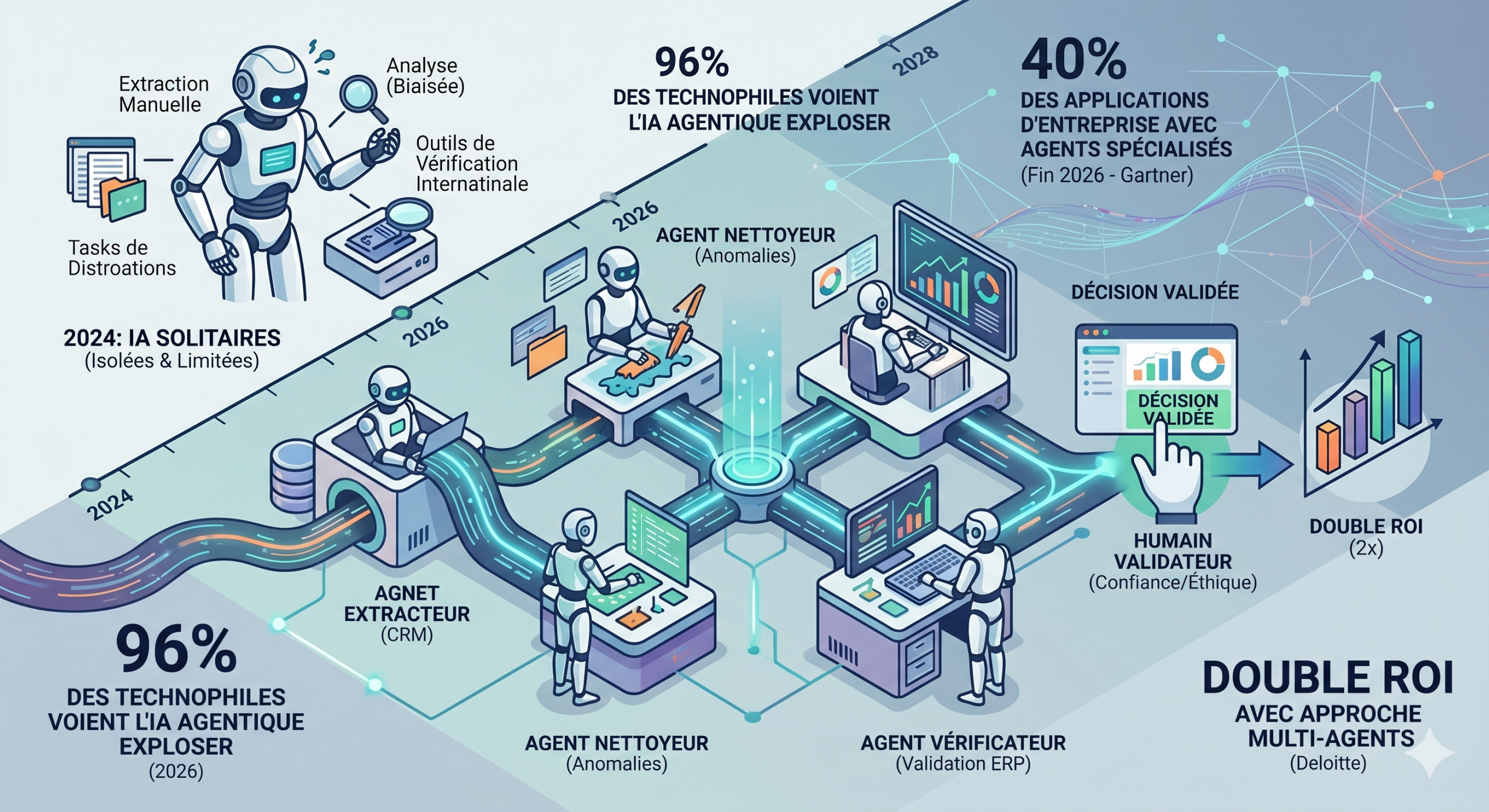
Les systèmes IA multi-agents remplacent les IA solitaires par des équipes collaboratives, imitant les équipes humaines pluridisciplinaires. Ils boostent précision (+21 points) et efficacité (30-50%) en data management, comme extraction-correction-analyse-vérification. Gartner prévoit 40% d’adoption en apps entreprise d’ici fin 2026. L’humain supervise éthique et créativité pour un travail hybride gagnant.