
Le domaine de la XAI (eXplainable AI) désigne les techniques ou des méthodes qui aident à expliquer le processus de prise de décision d’un modèle de Machine Learning donné. C’est une nouvelle branche de l’IA qui a bien sur un potentiel énorme. Expliquer la « raison du pourquoi » un modèle de Machine Learning a pris telle ou telle décision est en effet l’un des freins de l’adoption de cette discipline montante. Convaincre les métiers les utilisateurs en leur donnant plus de visibilité est donc devenu ces dernières années un enjeu de taille et ces nouveaux outils et les techniques de XAI deviennent de plus en plus sophistiquées pourvoir mettre de la lumière dans ces boites noires.
LIME (Local Interpretable Model-Agnostic Explanations) est l’une de ces méthodes dites locale (car elle va donner des explication du choix du modèle mais sur chaque valeur et non de manière globale sur tout un jeu de données) et agnostique (car il est possible d’utiliser LIME sur tout type de modèle de Machine Learning).
Comment fonctionne LIME ?
Sans aller dans de grand détails et explications mathématiques, LIME a de manière globale un fonctionnement ou du moins un principe de fonctionnement assez simple. Comme je vous l’ai dit en introduction LIME produit une explication des choix locaux d’un modèle. Cela signifie que LIME va se concentrer sur chaque valeur et non sur le jeu de données dans son ensemble: l’étude de l’importance des caractéristiques (ou « features ») du modèle s’effectue donc de manière microscopique. Mais comment ?
Tout d’abord et par rapport à une valeur donnée, LIME va générer aléatoirement d’autres individus qui n’existent bien sur pas dans le jeu de données mais qui son proches de la valeur pointée. Ensuite LIME va pondérer chaque valeur aléatoire par rapport à leur proximité de la valeur pointée, puis calculer la prédiction de ces valeurs. Pour terminer et comme on est à un niveau microscopique, LIME va créer un modèle linéaire qui va permettre de découvrir l’importance des variables sur la valeur.
Installer LIME
On peut trouver LIME sur Github ici, mais clairement le plus simple est d’utiliser PyPI:
pip install limePour la suite de ce tuto, je vais utiliser google colab avec le jeu de données des données immobilières de Californie qui est fournit et disponible dés le lancement de colab (Cf. /content/sample_data/california_housing_train.csv).
Attention car LIME n’est pas installé par défaut avec colab, il faut donc l’installer explicitement avec la commande pip ci-dessus.
Ensuite je vous propose d’installer quelques librairies:
import pandas as pd
from sklearn.model_selection import train_test_split,cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestRegressor
import random
import numpy as np
import matplotlib as plt
import warnings
warnings.filterwarnings("ignore")
from google.colab import data_table
# Display smart tables into colab ;-)
data_table.enable_dataframe_formatter()
import lime
from lime import lime_tabularCréation et entraînement d’un modèle
Tout d’abord on va agréger les données récupérées dans Google colab, ces données sont disponibles dans le volet de navigation de fichier à gauche. On regarde ensuite les colonnes (ou variables disponibles):
train = pd.read_csv('/content/sample_data/california_housing_train.csv')
test = pd.read_csv('/content/sample_data/california_housing_test.csv')
all_data = pd.concat([train, test], axis=0)
print(all_data.columns)Index(['longitude', 'latitude', 'housing_median_age', 'total_rooms', 'total_bedrooms', 'population', 'households', 'median_income', 'median_house_value'], dtype='object')L’étiquette est la colonne median_house_value.
Tout d’abord vérifions que l’on n’a pas de données manquantes:
all_data.isnull().sum()longitude 0
latitude 0
housing_median_age 0
total_rooms 0
total_bedrooms 0
population 0
households 0
median_income 0
median_house_value 0
dtype: int64Parfait, il n’y a aucune données non renseignées.
Vérifions ensuite que les données sont numériques:
all_data.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 20000 entries, 0 to 2999
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 longitude 20000 non-null float64
1 latitude 20000 non-null float64
2 housing_median_age 20000 non-null float64
3 total_rooms 20000 non-null float64
4 total_bedrooms 20000 non-null float64
5 population 20000 non-null float64
6 households 20000 non-null float64
7 median_income 20000 non-null float64
8 median_house_value 20000 non-null float64
dtypes: float64(9)
memory usage: 1.5 MBExcellent le jeu de données ne propose que des données numériques. On peut donc passer à la préparation de données. Pour cela on va créer une fonction de préparation très simple qui se contentera de sélectionner les features et les mettra à l’echelle:
scaler = StandardScaler()
# Function to prepare the data before modeling
def prepare_data(data, scale=True):
names = data.columns
if (scale == True):
# Scale data ?
scaled_data = scaler.fit_transform(data)
data = pd.DataFrame(scaled_data, columns=names)
X_features = names
# Or select the features ...
#X_features = ["median_income", "latitude", "longitude", "housing_median_age", "total_bedrooms", "total_rooms", "population", "households"]
y_label = ["median_house_value"] # Take the label
X = data[X_features] # Take the features
del X["median_house_value"] # remove the label
y = data[y_label]
# Create datasets for train & test
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
return x_train, x_test, y_train, y_test
# return value (un-scaled)
def get_value(val):
result = scaler.inverse_transform([np.concatenate((np.zeros(8), val))])
return result[0][8]Ensuite on va créer les jeux de données (entraînement et test) puis entraîner un modèle de Type forêt aléatoire:
# Prepare the all dataset
x_train, x_test, y_train, y_test = prepare_data(all_data)
# Train & Test
model = RandomForestRegressor()
model.fit(x_train.values, y_train.values.reshape(-1))
print(f"Score / training data: {round(model.score(x_train, y_train)*100, 1)} %")
print(f"Score / test data: {round(model.score(x_test, y_test)*100, 1)} %")Score / training data: 97.5 %
Score / test data: 80.9 %Les scores présentés à la fin montre une belle suspicion d’over-fitting. En effet on a un excellent score pour le jeu d’entrainement (trop sans doute) qui se dégrade netement avec les données de test. Mais ce n’est pas le sujet de cet article 😉
Résultats & prédictions
Effectuons une prédiction à partir du modèle entraîné sur toutes les valeurs du jeu de données:
y_train_predict = pd.DataFrame(model.predict(x_train))Regardons ensuite au travers d’une courbe la différence entre les valeurs prédites (bleu) et les valeurs attendues (rouge):
Y = y_train.copy()
Y["Prediction"] = y_train_predict.to_numpy()
Y.columns = ["Real", "Predict"]
Y = Y.sort_index()
Y["Id"] = Y.index
Y["Delta"] = Y["Real"] - Y["Predict"]
Y = Y.head(50)
plt.rcParams["figure.figsize"] = (50, 10)
Y["Real"].plot(color="#FF0000") # Red line
Y["Predict"].plot(color="#0000FF") # Blue line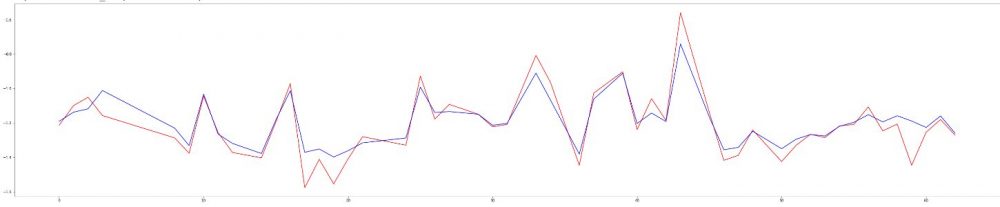
Utilisation de LIME
Voyons maintenant comment les caractéristiques ont influencées notre modèle sur certaines valeurs.
Tout d’abord il faut instancier LIME avec:
- Les caractéristiques au format numpy
- On précise que c’est un problème de régression (et pas de classification)
- On précise pour terminer les noms des colonnes
explainer = lime_tabular.LimeTabularExplainer(x_train.to_numpy(),
mode="regression",
feature_names= list(x_train.columns)
)Le tour est presque joué en réalité, mais je vous propose de créer une petite fonction qui va résumer et présenter tous les résultats. Cette fonction prend un index d’une donnée du dataset pour ensuite proposer de visualiser:
- Sa donnée prédite par le modèle (avec et sans mise à l’echelle)
- Sa donnée réelle
- Le delta entre la valeur prédite et la valeur réelle
- mais aussi et surtout les explications de LIME sur le résutat du modèle
def xai_display_for_value(idx):
print("----------------------------------------------------")
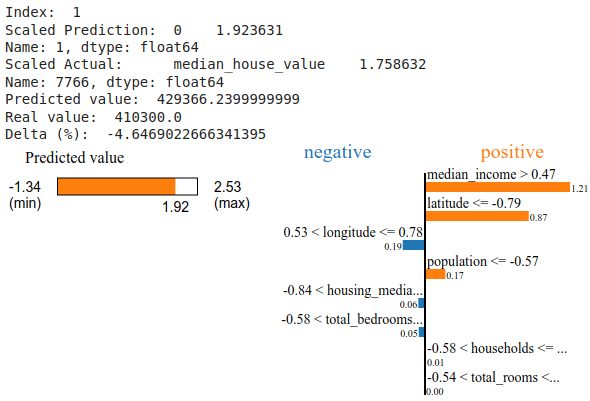
print("Index: ", idx)
print("Scaled Prediction: ", y_train_predict.iloc[idx])
print("Scaled Actual: ", y_train.iloc[idx])
print("Predicted value: ", get_value(y_train_predict.iloc[idx]))
print("Real value: ", get_value(y_train.iloc[idx]))
print("Delta (%): ", (get_value(y_train.iloc[idx]) - get_value(y_train_predict.iloc[idx])) * 100 / get_value(y_train.iloc[idx]) )
explanation = explainer.explain_instance(x_train.iloc[idx],
model.predict,
num_features=len(list(x_train.columns)))
explanation.show_in_notebook(show_table=True)
return explanationPour tester tout cela prenons une ligne au hasard:
i = random.randint(1, len(x_train))
xai_display_for_value(i)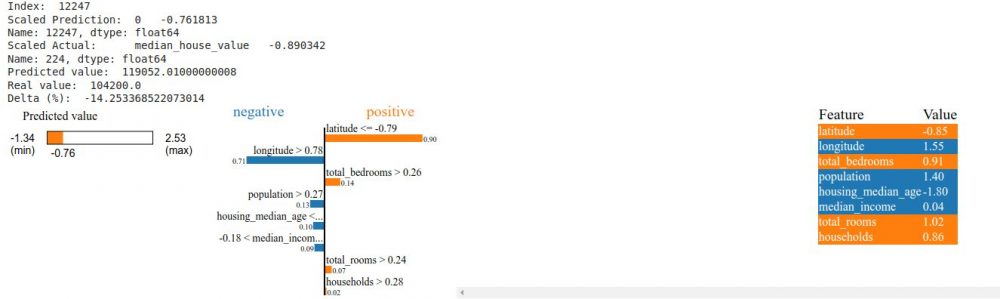
LIME présente de manière synthétique l’impact de chaque variable sur le choix final. Il est donc facile pour chaque valeur de voir quelle ou quelle caractéristiques a eu une influence positive ou négative sur le calcul final.
Récupérer les valeurs de LIME
On peut aussi utiliser les données calculées par LIME:
expl = xai_display_for_value(1)
expl.as_list()[('median_income > 0.47', 1.2105286311280485),
('latitude <= -0.79', 0.8663127017804445),
('0.53 < longitude <= 0.78', -0.18601783455962326),
('population <= -0.57', 0.1700758605340672),
('-0.84 < housing_median_age <= 0.03', -0.055667480769627416),
('-0.58 < total_bedrooms <= -0.25', -0.05216741340105752),
('-0.58 < households <= -0.23', 0.007839767845531052),
('-0.54 < total_rooms <= -0.24', 0.0005512754493286088)]Et pourquoi pas réaliser son propre graphique à barres:
print ("Generate a bar chart of feature contribution for this data sample:")
with plt.style.context("ggplot"):
expl.as_pyplot_figure()
Conclusion
Cet article est une très brève introduction à l’IA explicable (XAI) via l’utilisation de la solution locale et agnostique qu’est LIME. Avec son approche simple et rapide à mettre en place on voit d’ailleurs tout de suite comment LIME nous donne une meilleure vision de l’utilisation sous-jacente des caractéristiques dans la prise de décision d’un modèle de Machine Learning pour une valeur particulière. Cela fait de LIME une ressource très utile pour les data scientists !
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.