

Pourquoi filtrer les colonnes (« Features ») ?
Quand on récupère un jeu de données pour faire du Machine Learning, au delà de la validité des informations que l’on récupère on peut se demander à juste titre est-ce que toutes ces informations sont nécessaires. Alors bien sur quand on n’a qu’une dizaine de colonnes ce n’est pas vraiment un soucis, mais dés lors que l’on a des jeux de données qui présentent 100 voire plusieurs centaines/milliers de colonnes … on va devoir sérieusement se poser la question de limiter cette quantité d’information.
Mais comment ? par où commencer ? comment retirer simplement les colonnes (variables) qui ne sont pas très utiles et qui ne vont pas influer – beaucoup – sur la qualité de mon modèle de Machine Learning ?
La bonne question à se poser et quelles sont ces colonnes ou variables qui ont une réelle influence sur ma modélisation ?
Ok, je pose ma question dans l’autre sens: pensez-vous qu’une variable qui n’évolue pas beaucoup (à l’extrême une simple constante) influe beaucoup sur un modèle de Machine Learning ?
Evidemment que non !
Donc logiquement si on veut retirer les colonnes inutiles il nous suffit de retirer les colonnes qui ne varient pas beaucoup. Ca tombe bien il existe un outil statistique pour ça: la Variance.
Pour rappel, la Variance est un outil de mesure statistiques qui consiste à calculer la distance des points par rapports à la moyenne. C’est donc un excellent moyen de savoir si les données d’une colonne sont constantes ou au contraire extrêmement variées.
Un peu de pratique
Nous allons utiliser Python et Google colab. Par ailleurs nous allons prendre un jeu de données très simple afin de bien comprendre l’approche proposée dans cet article.
import pandas as pd
from sklearn.feature_selection import VarianceThreshold
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
from google.colab import data_table
# Display smart tables into colab ;-)
data_table.enable_dataframe_formatter()
tab = [[4,1,0,0,0,0,1,5,4,0,0,0,1],
[3,8,0,1,0,0,1,5,1,1,4,5,1],
[2,2,0,0,0,0,8,1,4,1,2,8,1],
[4,7,2,0,0,0,1,2,2,0,4,9,2],
[2,1,0,0,5,0,1,5,4,1,4,8,1]]
dataset = pd.DataFrame(tab)
Voilà, nous avons un jeu de données de 13 colonnes et 5 lignes:
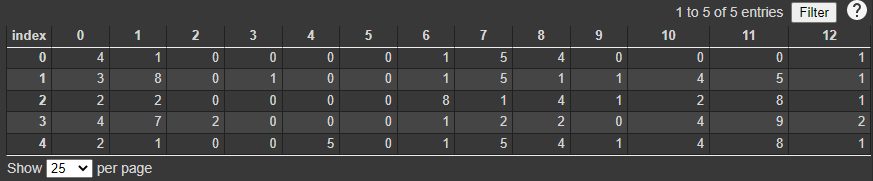
Visualisation ces données et calculons la Variance pour chaque colonne. Nous allons créer une grille qui nous affichera un diagramme à barre par colonne:
figure(figsize=(20, 15), dpi=80)
def displayColumnDistribution(_dataset):
for i in range(dataset.shape[1]):
plt.subplot(4, 4, i+1)
plt.title('Column ' + str(i) + ', Var=' + str(np.var(dataset[i])))
x = np.arange(dataset.shape[0])
plt.bar(x, dataset[i])
displayColumnDistribution(dataset)
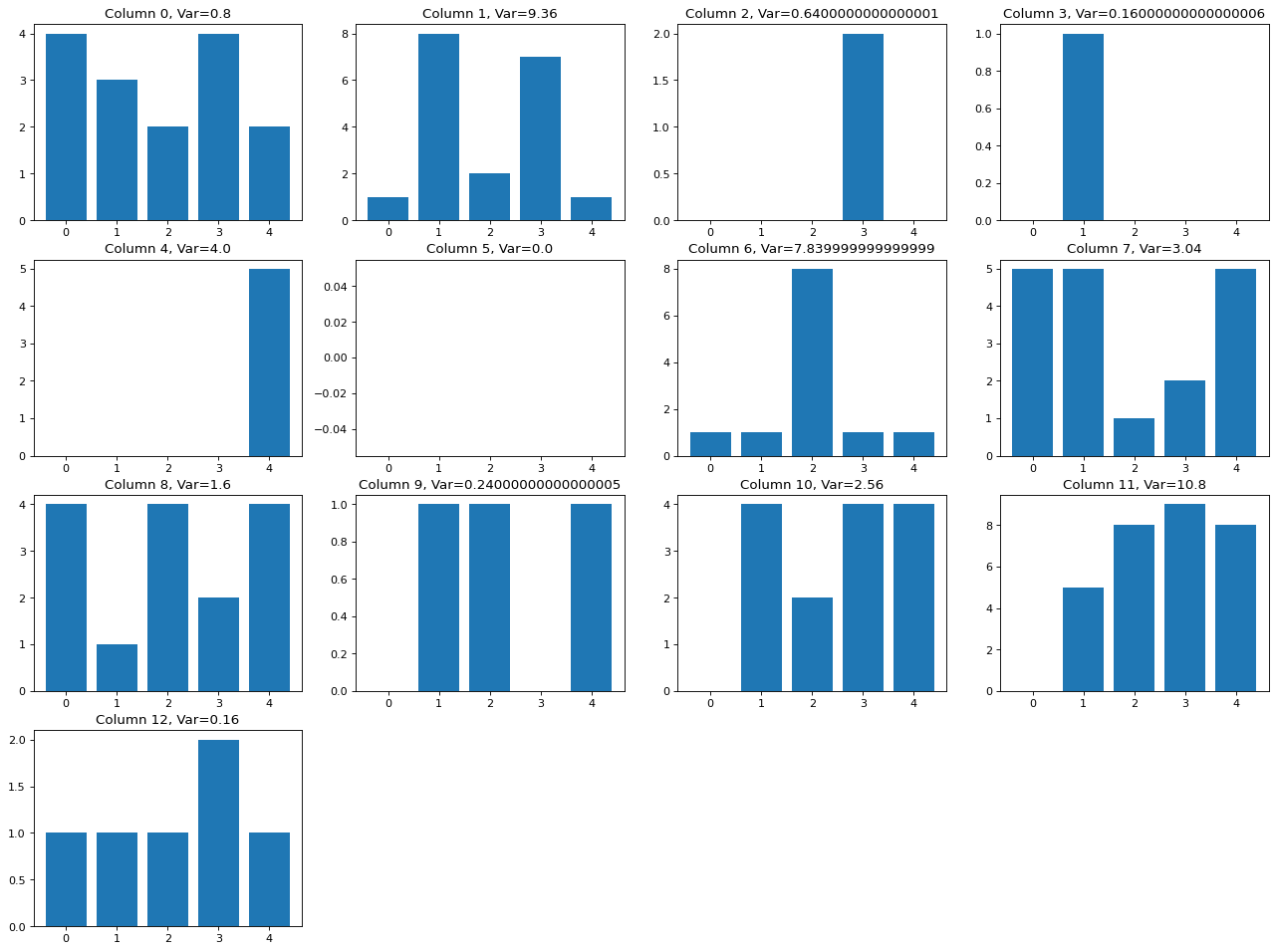
Note: Ici nous calculons la variance avec la fonction numpy (np.var()), pour plus d’infos sur le calcul de la variance, je vous invite à lire cet article.
import numpy as np
for i in range(dataset.shape[1]):
print("Variance for feature N°", str(i), ": ", np.var(dataset[i]))
Variance for feature N° 0 : 2.5600000000000005
Variance for feature N° 1 : 0.16000000000000003
Variance for feature N° 2 : 0.6400000000000001
Variance for feature N° 3 : 0.16000000000000006
Variance for feature N° 4 : 4.0
Variance for feature N° 5 : 0.0
Variance for feature N° 6 : 7.839999999999999
Variance for feature N° 7 : 3.04
Variance for feature N° 8 : 1.6
Variance for feature N° 9 : 0.24000000000000005
Variance for feature N° 10 : 2.56
Variance for feature N° 11 : 10.8
Variance for feature N° 12 : 0.16Filtrons les colonnes de faible variance
Pour cela nous allons utiliser sklearn et sa fonction VarianceThreshold().
Utilisons la fonction telle quelle sur notre jeu de données:
vt = VarianceThreshold() # Threshold default is 0 _ = vt.fit(dataset) var_vector_mask = vt.get_support() var_vector_mask
array([ True, True, True, True, True, False, True, True, True,
True, True, True, True])La fonction get_support() renvoit en fait un vecteur de booleen. Si la valeur est True celà signifie que la colonne peut être conservée, dans le cas contraire la variance de la colonne doit être supprimée. Pour savoir si la colonne doit être supprimée la fonction calcule la variance de la colonne et la compare à un seuil. Par défaut le seuil est à zéro. Cela signifie que seules les colones à variance nulle (c’est à dire celles qui ont une valeur constante) seront supprimées.
Dans notre exemple, nous avons une valeur False au 6ème rang ce qui signifie que cette colonne porte toujours les mêmes valeurs, c’est en effet le cas car cette colonne ne contient que la valeur zéro.
Appliquons le masque à notre jeu de données pour le filtrer et donc lui retirer automatiquement cette colonne 6:
dataset_result = dataset.loc[:, var_vector_mask]
Changement de seuil
Bien sur il est possible de changer le seuil de filtrage de la variance. Nous avons des variances qui vont de 0 à 10, mettons notre seuil à 1 pour voir le niveau de filtrage:
vt = VarianceThreshold(threshold=1) # Fit _ = vt.fit(dataset) # Get the boolean mask mask = vt.get_support() dataset_reduced = dataset.loc[:, mask] dataset_reduced.shape
(5, 7)Nous avons filtré ici 5 colonnes.
Au lieu d’utiliser les masques tel que nous l’avons fait ici il est aussi possible de filtrer directement les colonnes avec la fonction sklearn fit_transform() pour le même résultat:
selector = VarianceThreshold(threshold=1) dataset_reduced = selector.fit_transform(dataset) dataset_reduced
array([[1, 0, 1, 5, 4, 0, 0],
[8, 0, 1, 5, 1, 4, 5],
[2, 0, 8, 1, 4, 2, 8],
[7, 0, 1, 2, 2, 4, 9],
[1, 5, 1, 5, 4, 4, 8]])Conclusion
Nous venons de voir une méthode simple qui permet de filtrer vos colonnes dés lors que vous en avez trop par exemple. La seule difficulté ici est de bien régler le seuil de variance afin de ne pas trop retirer d’informations. Définitivement appliquer cette fonction avec le seuil à zéro ne comporte aucun risque puisque la modélisation n’en prendra pas compte.
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.