

Dans les deux articles précédents nous avons annoté nos images puis nous avons configuré darknet afin de pouvoir créer notre propre modèle de détection de documents. Dans ce dernier article de la série YOLO v4 nous allons lancer l’entrainement de notre modèle avec darknet, puis nous allons bien sur le tester.
Entraînement du modèle
Nous y voilà ! après toutes ces configurations nous allons pouvoir – enfin – déclencher l’entrainement de notre modèle YOLO sur des images personnalisées afin de détecter des documents dans toute image.
Pour ce faire, continuez à utiliser le même Notebook dans Google colab et ajoutez-y une cellule:
%cd "/content/drive/MyDrive/Colab Notebooks/YOLO/darknet" !chmod +rwx ./*
Nous allons ensuite lancer la commande (en mode ligne de commande) qui permet d’indiquer à darknet de lancer l’entrainement d’un nouveau modèle:
!./darknet detector train doc_data/document.data doc_data/document_yolov4.cfg doc_data/yolov4.conv.137 -dont_show -map
Remarquez les parametres :
- doc_data/document.data doc_data/document_yolov4.cfg qui est notre fichier de configuration du modèle YOLO
- doc_data/yolov4.conv.137 est le fichier des poids pré-entrainé (Cf. transfer Learning)
Une fois lancée le traitement peut durer des heures (voire plus selon le nombre de classes et de fichier d’entraînement).
Suivi d’exécution de l’entraînement
Il y a deux façon de suivre le traitement. Bien sur dans Google colab vous allez voir bon nombre de logs défiler.
Regardez de plus près et vous y trouverez notament:
- Le numéro d’itération (epochs). Ci-dessous nous en sommes à l’itération N°1906
- Le taux de perte: avg Loss
(next mAP calculation at 2000 iterations)
1906: 0.756686, 1.466187 avg loss, 0.000013 rate, 22.043027 seconds, 114360 images, 1.476337 hours left
Loaded: 11.882894 seconds - performance bottleneck on CPU or Disk HDD/SSD
v3 (iou loss, Normalizer: (iou: 0.07, obj: 1.00, cls: 1.00) Region 139 Avg (IOU: 0.361245), count: 1, class_loss = 0.201240, iou_loss = 0.875642, total_loss = 1.076881
v3 (iou loss, Normalizer: (iou: 0.07, obj: 1.00, cls: 1.00) Region 150 Avg (IOU: 0.766196), count: 13, class_loss = 1.758310, iou_loss = 3.690968, total_loss = 5.449277
v3 (iou loss, Normalizer: (iou: 0.07, obj: 1.00, cls: 1.00) Region 161 Avg (IOU: 0.822551), count: 40, class_loss = 1.684688, iou_loss = 3.024157, total_loss = 4.708845
total_bbox = 3317, rewritten_bbox = 0.000000 % L’autre manière de suivre les traitement mais surtout aussi de vérifier la courbe d’apprentissage de notre modèle est d’ouvrir l’image que darknet dépose régulièrement dans la racine de darknet.
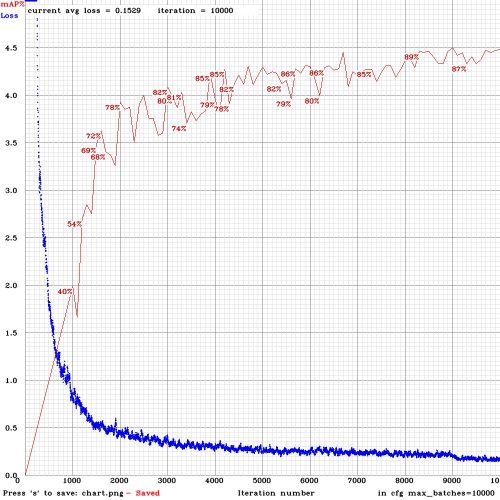
Le fichier en question se nomme chart_document_yolov4.png :
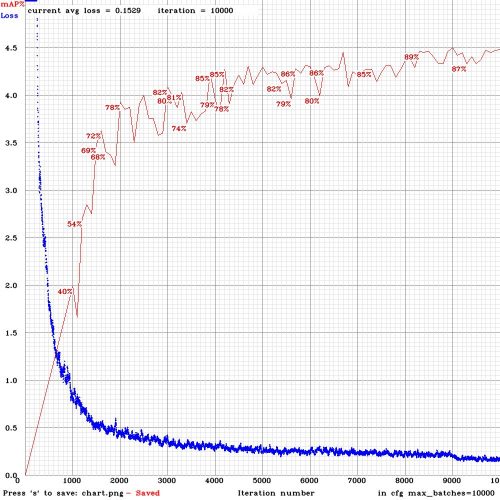
La courbe en bleu présente l’erreur (Loss) et c’est la courbe que vous allez pouvoir suivre tout au long du traitement. Inutile de préciser qu’il serait bon qu’elle décroissent très rapidement comme la mienne ci-dessus.
En cas d’erreur ?
En cas d’erreur, typiquement ce qui risque de vous arriver est que Google colab stoppe le traitement en vous signifiant que votre temps d’utilisation de GPU est fini et que vous devez attendre (jusque quand, ce n’est pas précisé mais en général au moins une journée). Bref, votre traitement est dans les choux ! la bonne nouvelle est que darknet effectue des sauvegardes régulièrement. Pour modifier ces paramètres de backup automatique il suffit de modifier le fichier cfg que nous avons créé dans l’article précédent :
- burn_in=1000 (permet créer une copie du le fichier de poids après la millième itération)
- max_batches = 2000 (précise a darknet de s’arreter après 2000 itérations)
L’autre bonne nouvelle, en cas d’erreur est qu’il suffit de lancer la ligne de commande pour que darknet reprenne (presque) où il en était. Attention ce n’est pas exactement la même commande, tapez celle-ci:
!./darknet detector train doc_data/document.data doc_data/document_yolov4.cfg backup/document_yolov4_last.weights -dont_show -map
En effet, le dernier fichier de poids mis de coté par darknet se nomme document_yolov4_last.weights
Traitement terminé ?
Une fois l’entraînement terminé, vous devez avoir affiché dans Google colab quelque chose comme ceci :
0.789124, total_loss = 1.830107
total_bbox = 51907, rewritten_bbox = 0.050090 %
(next mAP calculation at 2000 iterations)
2000: 0.973554, 1.223958 avg loss, 0.000013 rate, 22.242532 seconds, 120000 images, 0.775685 hours left
Resizing to initial size: 416 x 416 try to allocate additional workspace_size = 124.60 MB
CUDA allocate done!
calculation mAP (mean average precision)...
Detection layer: 139 - type = 28
Detection layer: 150 - type = 28
Detection layer: 161 - type = 28
60
detections_count = 317, unique_truth_count = 98
class_id = 0, name = document, ap = 78.59% (TP = 75, FP = 16)
for conf_thresh = 0.25, precision = 0.82, recall = 0.77, F1-score = 0.79
for conf_thresh = 0.25, TP = 75, FP = 16, FN = 23, average IoU = 63.93 %
IoU threshold = 50 %, used Area-Under-Curve for each unique Recall
mean average precision (mAP@0.50) = 0.785907, or 78.59 %
Total Detection Time: 40 Seconds
Set -points flag:
`-points 101` for MS COCO
`-points 11` for PascalVOC 2007 (uncomment `difficult` in voc.data)
`-points 0` (AUC) for ImageNet, PascalVOC 2010-2012, your custom dataset
mean_average_precision (mAP@0.50) = 0.785907
New best mAP!
Saving weights to backup/document_yolov4_best.weights
Saving weights to backup/document_yolov4_2000.weights
Saving weights to backup/document_yolov4_last.weights
Saving weights to backup/document_yolov4_final.weights
If you want to train from the beginning, then use flag in the end of training command: -clear Clairement vous voyez que ma précision est de 78% (0.785907), ce qui n’est pas terrible en réalité et c’est surtout du au fait que mon jeu d’apprentissage n’était pas terrible. Nous allons quand même voir ce que ça donne. Remarquez aussi que darknet propose plusieurs fichiers de poids dont celui ayant le meilleur score (document_yolov4_best.weight).
Test du résultat
Nous pouvons bien sur tester notre nouveau modèle. Pour cela il suffit de créer une nouvelle cellule dans Google colab :
%cd "/content/drive/MyDrive/Colab Notebooks/YOLO/darknet" !chmod +rwx ./* !./darknet detector test doc_data/document.data "/content/drive/MyDrive/Colab Notebooks/YOLO/darknet/doc_data/document_yolov4.cfg" "/content/drive/MyDrive/Colab Notebooks/YOLO/oc_data/yolov4_document.weights" "/content/drive/MyDrive/Colab Notebooks/YOLO/darknet/doc_data/doc_images/(1).jpg"
Le résultat peut paraitre pas mal à première vue. Le cadre est bien positionné et on voit que le document a score plutot élevé (100%) … en fait si le score est excellent ici, faites quelques autres essais et vous constaterez vite que 78% n’est pas un score terrible pour ce type de modèle.

Conclusion
A ceux qui esperaient avoir un modèle YOLO v4 opérationnel pour la détection de documents dans une image, j’image votre déception ! mais ne vous en faites pas car si le score n’est terrible il peut être considérablement amélioré avec de bonnes données pour l’entrainement. En fait la véritable clé d’un bon modèle c’est le tuple gagnant : Bonnes données, annotations de qualité et bon modèle.
N’hésitez pas a jeter un coup d’œil sur le Notebook que j’ai utilisé ici.
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.
Bonjour,
Merci pour les explications claires de la démarche à suivre !
Une fois que j’ai obtenu mon modèle entrainé avec une précision convenable, je souhaite pouvoir l’exploiter directement sur le flux vidéo d’une caméra mais je ne sais pas tellement comment faire… (je découvre la programmation et les CNN depuis environ un mois donc cela fait beaucoup d’infos…^^)
Merci pour le retour 😉