

Du NLP (Natural Language Processing) oui mais avec quoi ?
Chose promise, chose due ! je vous avais fait part dans mon article sur les sac de mots que nous irions plus loin avec du NLP, et bien nous y voilà. Maintenant, quel outillage choisir ? quelle librairie utiliser ? en effet le monde Python semble se déchirer entre deux package : l’un historique NLTK (Natural Language Toolkit) et le petit nouveau SpaCy (2015).
Loin de moi l’idée de faire un comparatif de ces deux très bonnes librairies que sont NLTK et SpaCy. Il y a du pour et du contre chez chacune, mais la facilité d’utilisation, la disponibilité de vecteurs de mots pré-entraînés ainsi que des modèles statistiques dans plusieurs langues (anglais, allemand et espagnol) mais surtout en Français m’ont définitivement fait basculer vers SpaCy. Place aux jeunes 😉
Ce petit tuto va donc vous montrer comment utiliser cette librairie.
Installer et utiliser la librairie
Cette librairie n’est pas installée par défaut avec Python. Pour l’installer le plus simple est de lancer une ligne de commande et de faire appel à l’utilitaire pip comme suit :
pip install -U spaCy
python -m spacy download fr
python -m spacy download fr_core_news_mdNB: Les deux dernières commandes permettent d’utiliser les modèles déjà entrainés en Français. Ensuite pour utiliser SpaCy il faut importer la librairie mais aussi l’initialiser avec la bonne langue avec la directive load()
import spacy
from spacy import displacy
nlp = spacy.load('fr')La tokenisation
La première chose que nous allons faire est de « tokeniser » une phrase afin de la découper grammaticalement. La tokenisation est l’opération qui consiste à segmenter une phrase en unités « atomiques » : les tokens. Les tokenisations les plus courantes sont le découpage en mots ou bien en phrases. Nous allons commencer par les mots et pour cela nous utiliserons la classe token de SpaCy :
import spacy
from spacy import displacy
nlp = spacy.load('fr')
doc = nlp('Demain je travaille à la maison')
for token in doc:
print(token.text)Le code précédent découpe la phrase ‘Demain je travaille à la maison’ et affiche chaque élément
Demain
je
travaille
à
la
maison
en
FranceRien de très impressionnant pour l’instant, nous avons juste découpé une phrase. Regardons maintenant de plus près ce qu’a fait en plus SpaCy lors de ce découpage :
doc = nlp("Demain je travaille à la maison.")
for token in doc:
print("{0}\t{1}\t{2}\t{3}\t{4}\t{5}\t{6}\t{7}\t{8}".format(
token.text,
token.idx,
token.lemma_,
token.is_punct,
token.is_space,
token.shape_,
token.pos_,
token.tag_,
token.ent_type_
))L’objet token est bien plus riche qu’il n’y parait et renvoit beaucoup d’informations grammaticales sur les mots de la phrase :
Demain 0 Demain False False Xxxxx PROPN PROPN___
je 7 il False False xx PRON PRON__Number=Sing|Person=1
travaille 10 travailler False False xxxx VERB VERB__Mood=Ind|Number=Sing|Person=1|Tense=Pres|VerbForm=Fin
à 20 à False False x ADP ADP___
la 22 le False False xx DET DET__Definite=Def|Gender=Fem|Number=Sing|PronType=Art
maison 25 maison False False xxxx NOUN NOUN__Gender=Fem|Number=Sing
. 31 . True False . PUNCT PUNCT___ Cet objet nous informe de l’utilisation/qualification de chaque mot (pour plus de détails allez dans l’aide de SpaCy):
- text: Le texte/mot original
- lemma_: la forme de base du mot (pour un verbe conjugué par exemple on aura son infinitif)
- pos_: Le tag part-of-speech (détail ici)
- tag_: Les informations détaillées part-of-speech (détail ici)
- dep_: Dépendance syntaxique (inter-token)
- shape: format/pattern
- is_alpha: Alphanumérique ?
- is_stop: Le mot fait-il partie d’une Stop-List ?
- etc.
Tokenison maintenant des phrases. En fait le travail est déjà fait (Cf. documentation) et il suffit de récupérer l’objet sents du document :
doc = nlp("Demain je travaille à la maison. Je vais pouvoir faire du NLP")
for sent in doc.sents:
print(sent)Le résultat :
Demain je travaille à la maison.
Je vais pouvoir faire du NLPSpaCy permet bien sur de récupérer les phrases nominales (cad les phrases sans verbes):
doc = nlp("Terrible désillusion pour la championne du monde")
for chunk in doc.noun_chunks:
print(chunk.text, " --> ", chunk.label_)Terrible désillusion pour la championne du monde --> NPNER
SpaCy dispose d’un système de reconnaissance d’entités statistiques (NER ou Named Entity Recognition) très performant et qui va assigner des étiquettes à des plages contiguës de tokens.
doc = nlp("Demain je travaille en France chez Tableau")
for ent in doc.ents:
print(ent.text, ent.label_)Le code précédent parcours les mots dans leur contexte et va reconnaître que la France est un élément de localisation et que Tableau est une organisation (commerciale) :
France LOC
Tableau ORGDépendances
Personnellement je trouve que c’est la fonction la plus impressionnante car grâce à elle nous allons pouvoir recomposer une phrase en reliant les mots dans leur contexte. Dans l’exemple ci-dessous nous reprenons notre phrase et indiquons chaque dépendance avec les propriétés dep_
doc = nlp('Demain je travaille en France chez Tableau')
for token in doc:
print("{0}/{1} <--{2}-- {3}/{4}".format(
token.text,
token.tag_,
token.dep_,
token.head.text,
token.head.tag_))Le résultat est intéressant mais pas vraiment lisible :
Demain/PROPN___ <--advmod-- travaille/VERB__Mood=Ind|Number=Sing|Person=1|Tense=Pres|VerbForm=Fin
je/PRON__Number=Sing|Person=1 <--nsubj-- travaille/VERB__Mood=Ind|Number=Sing|Person=1|Tense=Pres|VerbForm=Fin
travaille/VERB__Mood=Ind|Number=Sing|Person=1|Tense=Pres|VerbForm=Fin <--ROOT-- travaille/VERB__Mood=Ind|Number=Sing|Person=1|Tense=Pres|VerbForm=Fin
en/ADP___ <--case-- France/PROPN__Gender=Fem|Number=Sing
France/PROPN__Gender=Fem|Number=Sing <--obl-- travaille/VERB__Mood=Ind|Number=Sing|Person=1|Tense=Pres|VerbForm=Fin
chez/ADP___ <--case-- Tableau/NOUN__Gender=Masc|Number=Sing
Tableau/NOUN__Gender=Masc|Number=Sing <--obl-- travaille/VERB__Mood=Ind|Number=Sing|Person=1|Tense=Pres|VerbForm=FinHeureusement SpaCy a une fonction de trace pour rendre ce résultat visuel. Pour l’utiliser vous devez importer displacy:
from spacy import displacy
displacy.render(doc, style='dep', jupyter=True, options={'distance': 130})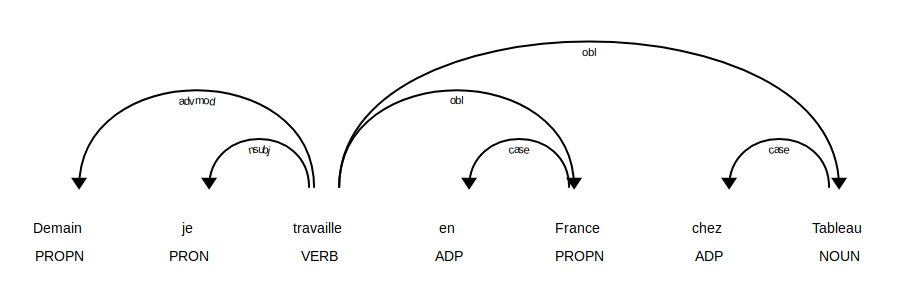
C’est tout de suite plus parlant comme ça non ?
Voilà qui conclu cette première partie sur l’utilisation de NLP avec la librairie SpaCy. Pour les curieux du NLP, n’hésitez pas à lire aussi mon article sur NLTK.
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.
Très intéressant et très utile.
Je passe à Spacy !
J’analyse le grand débat national comme exemple d’une analyse d’opinions liées aux questions.
Dominique Pignon
Directeur de recherches cnrs
J’ai fait quelques tests avec spaCy en français avec les derniers pack 2020. Je suis assez surpris par la renommée de l’outil, le résultat est plutôt nul. La détection des verbes marche plutôt pas mal, mais avec un bête algo associé à une racinisation et un dico FR, j’aurais explosé ses performances. Concernant la détection des entités nommé, c’est ni fait ni à faire. Le résultat est complètement hasardeux et absurde. Pour le coup un algo de détection des termes ucfirst associé à une regexp détectant les mots après les déterminants aurait fait 100x mieux. C’est vraiment décevant.
Il faut entraîner le modèle sur vos data si vous voulez améliorer les performances de spaCy.
C’est vrai que les modèles entraînés en Français ne sont pas au niveaux de ceux en Anglais (comme très souvent d’ailleurs). Rien de magique non plus avec le NLP il faut souvent retravailler les résultats obtenus ou mieux préparer les données en amont. @AtomBusiness, pourrais-tu peut être nous faire partager plus en détail ton expérience ?
Oui c’est le sentiment que j’en ai eu en testant. J’ai l’impression qu’il a été entraîné sur de l’anglais et adapté pour le français.
Sur des phrases longues, j’avais de très mauvais résultats, donc j’ai testé sur des phrases très courtes, et je vous laisse voir le résultat : https://imgur.com/a/il0YMc2
Donc pour l’instant je suis dos au mur, je ne sais pas quel outils me permettrait d’extraire mes verbes/entitées nommées efficacement dans une phrase. Je misais beaucoup sur spaCy, mais en l’état il est inutilisable dans une industrialisation sérieuse.
les modèles de spacy sont très nul en français
Comme souvent, les communautés francophone ne sont pas assez nombreuses (n’oublions pas qu’on est sous licence MIT). Du coup, il est vrai que les modèles Fr ne sont pas encore au niveau.
Pour info et retour d’expérience …
Je développe un assistant vocal en français entres autres php (Symfony) et j’ai regardé un peu spaCy.
Je rejoins les commentaires plutôt négatifs ci-dessus sur son intérêt et ses performances du moins en français.
Outre le fait que l’usage soit plutôt en python qui aurait donc demandé dans mon architecture un wrapper php, j’ai développé des fonctions simples d’analyse lexicale et syntaxique qui rendent le service.
Pour la tokenisation et la classification, j’ai utilisé la bibliothèque php ai-ml.
Cet assistant vocal s’intègre dans un projet de smart-home qui fonctionne depuis quelques années.