
Suite à l’un de mes précédent article sur le RAG (Retrieval Augmented Generation), et quelques commentaires pertinents de lecteurs, je me dois d’aller plus dans le détail sur cette technologie. En fait je vais faire mieux que cela, et je vais décomposer pierre par pierre cette technique et vous montrer qu’elle n’est pas très complexe finalement.
Commençons par un article explicatif, et les prochain seront eux focalisés sur la mise en œuvre étape par étape.
Qu’est-ce que le RAG ?
Tout d’abord un peut de contexte. Comme nous le savons, les grands modèles linguistiques (LLM) sont formés sur des ensembles de données spécifiques. Ils sont de plus en plus performants mais peuvent dans certains cas manquer de connaissances, en particulier dans le contexte de données d’entreprise ou confidentielles. En fait, leur compétence se limite aux informations contenues dans leur formation (training), ce qui limite par là même leur valeur potentielle. Le défi consiste donc à exploiter les capacités linguistiques des LLM tout en gérant des données spécifiques (hors entrainement), souvent stockées dans des bases de données et dans divers formats de documents (PDF, DOC, etc.).
Un bon exemple pourrait consister à interroger des informations spécifiques dans un document ou à extraire des détails pertinents de plusieurs documents, par exemple en récupérant la date de candidature d’un contrat. Cela nécessite une solution qui permette aux LLM de fonctionner efficacement avec ces données spécifiques … mais voilà ces LLM comment nous l’avons dit ne connaissent pas tout (et heureusement quelque part) !
Fonctionnement
Trouver un équilibre entre l’exploitation des capacités du langage LLM et le respect de la confidentialité et de la sécurité des données d’entreprise est donc primordial pour une intégration réussie. Et c’est souvent ici qu’intervient le RAG !
Cette technique utilise un processus en deux étapes :
- LeRetriever qui identifie les passages pertinents à partir d’un grand ensemble de données
- Le Générateur qui produit un texte cohérent et contextuellement pertinent basé sur les informations récupérées.
Cette approche en deux étapes améliore la capacité du modèle à générer des réponses ou des résumés de haute qualité et dans un contexte précis. Le RAG a démontré son succès dans diverses tâches, telles que la réponse aux questions et la synthèse, en intégrant efficacement des connaissances externes via des mécanismes de récupération dans le processus de génération.
Le RAG parvient à une « compréhension contextuelle » robuste en utilisant la récupération d’informations pour capturer le contexte pertinent à partir d’ensembles de données étendus. Cette intégration des connaissances récupérées (à partir de données externes) améliore ainsi la capacité du RAG à générer des réponses ou des résumés plus juste, mais aussi plus pertinents sur le plan contextuel. Particulièrement efficace avec des documents longs où le maintien du contexte est crucial, le RAG surmonte ainsi une limitation courante trouvée dans les LLM. L’approche en deux étapes, impliquant à la fois la récupération et la génération, contribue ainsi à une sélection de contenu raffinée, aboutissant à la production d’un texte généré beaucoup plus cohérent limitant par là même les soucis potentiels d’hallunications.
Le RAG étape par étape
Pour illustrer le RAG prenons un exemple très simple. Imaginons que l’on désire poser une question sur un document particulier (ici on prendra comme exemple la déclaration a la nation de Joe Biden en 2023) … imaginons que l’on veuille savoir combien le président à promis de création d’emplois dans son discours ! si notre LLM n’a pas été entrainé avec ces données, il n’y a aucune chance qu’il puisse répondre à ce type de question.
Voici donc un exemple typique qui reprend en gros les différentes étapes du RAG (bien sur il y a autant de variantes que de cas d’utilisations):
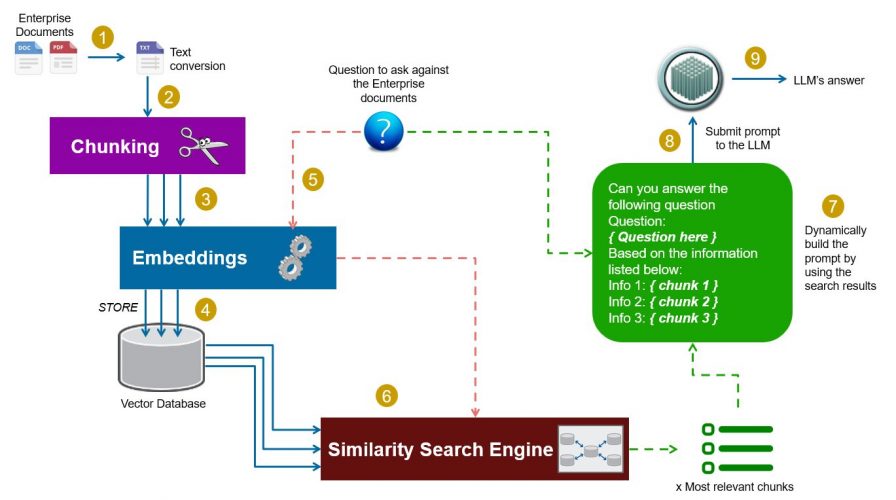
- Extraction des données du document (par exemple de PDF vers texte)
- Si la fenêtre contextuelle (LLM Context Window) ne peut pas contenir tout le document (principalement le cas), il est alors nécessaire de fragmenter le document: c’est ce que l’on appelle le chunking. L’idée est très simple et consiste a découper le texte d’origine en morceaux (chunks).
- Chaque morceau (chunk) de document ensuite doit ensuite être vectorisé. Dans le contexte LLM, on parle d’embeddings.
- Si nécessaire, on peut stocker ces intégrations dans une base de données vectorielle (Vector Store ou Vector DB) pour une recherche ou une utilisation ultérieure.
- On vectorise aussi la question à poser au LLM (embeddings)
- Nous appliquons une recherche de similarité sur les vecteurs stockés (ou en mémoire) et la question et récupérons les vecteurs et données les plus pertinents. Il est également possible de les utiliser à la volée et d’utiliser un moteur de recherche de similarité comme FAISS (de Meta).
- On construit ensuite le prompt avec la question et les morceaux les plus pertinents (vecteurs/données récupérés au préalable)
- On soumet le prompt au LLM
- On récupère la réponse, et voila !
Token vs Embeddings
Coté vocabulaire il est important de différencier dés maintenant token et embeddings (vecteurs).
Jetons
Un jeton est une unité de base d’une séquence d’apprentissage automatique. Dans le contexte des LLM, les jetons sont généralement des mots ou des sous-mots (comme des caractères ou des radicaux) qui composent une phrase. Le processus de conversion d’une phrase en une séquence de jetons est appelé tokenisation.
Embeddings
Un embedding est une représentation vectorielle d’un jeton. Il s’agit d’un processus qui mappe chaque jeton à un vecteur de nombres réels, qui capture les propriétés sémantiques et syntaxiques du jeton. Les embeddings sont utilisés pour encoder des informations linguistiques complexes dans un format numérique que les LLM peuvent traiter.
Suite ?
Vous avez compris les grandes lignes du RAG ? dans les prochains articles nous allons détailler chacune de ces étapes, comment les implémenter simplement et surtout faire tourner tout cela sur un ordinateur de bureau (si si !).
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.