
NLPCloud.io est une API permettant de facilement utiliser le NLP en production. L’API se base sur les modèles pré-entrainés de spaCy et Hugging Face (basés sur les transformers). Elle permet aussi d’utiliser ses propres modèles spaCy. NLPCloud.io supporte à ce jour les fonctionnalités suivantes: extraction d’entités (NER), analyse de sentiments, classification de texte, résumé de texte, réponse aux questions, et étiquetage morpho-syntaxique (POS tagging).
L’API est utilisable gratuitement à raison de 3 requêtes par minute, ce qui permet de facilement tester la qualité des modèles proposés. Ensuite le premier plan payant est à 29€ par mois (pour 15 requêtes par minute).
Voyons dans ce tuto comment utiliser l’API.
Pourquoi NLP Cloud ?
La mise en production des modèles est souvent un challenge à l’origine de l’échec de nombreux projets d’IA. Les modèles NLP sont extrêmement gourmands en ressources, et assurer la haute disponibilité de ces modèles en production, tout en optimisant leur temps de réponse, coûte cher en terme d’infratructure et demande des compétences poussées en DevOps, en développement, et en IA.
Le but de NLP Cloud est de permettre aux entreprises de rapidement déployer leurs modèles en production, sans compromis de qualité, et à des prix raisonnables.
Créer un compte
Inscription
L’inscription se fait en quelques secondes. Rendez vous sur https://nlpcloud.io/home/register et renseignez email et mot de passe.
Récupération du token API
Une fois l’inscription faite, vous arrivez tout de suite sur votre dashboard vous affichant votre token d’API. Gardez ce dernier précieusement, vous l’utiliserez pour tous vos appels à l’API.
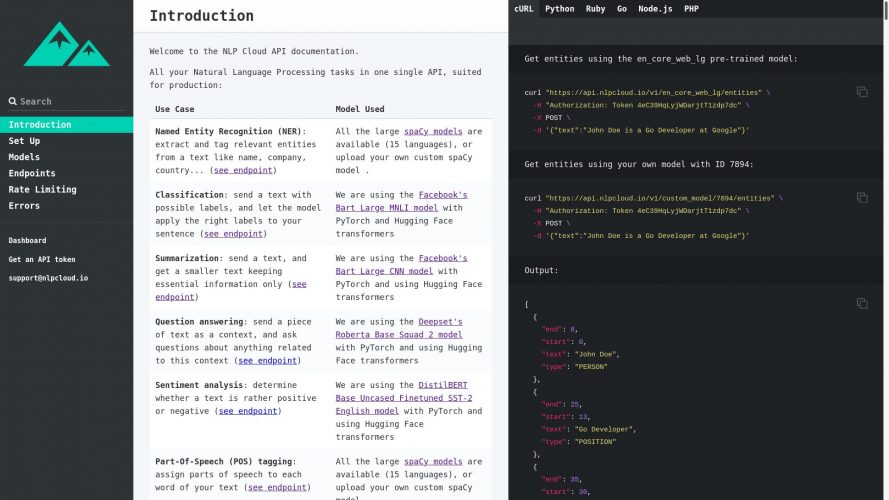
Documentation
Plusieurs bouts de code vous sont donnés dans votre dashboard afin de vous aider à démarrer rapidement. Pour aller plus loin, vous pouvez consulter la documentation.
Utiliser l’API NLPCloud.io
NLP Cloud fournit, clé en main, la plupart des fonctionnalités NLP classiques, soit via des modèles spaCy ou Hugging Face pré-entrainés, soit en uploadant vos propres modèles spaCy.
Bibliothèques clients
Afin de faciliter l’utilisation de l’API, NLP Cloud fournit des bibliothèques client en plusieurs langages (Python, Ruby, PHP, Go, Node.js). Dans le suite de ce tuto, nous allons utiliser la bibliothèque Python.
Pour installer la bibliothèque Python, utilisez PIP:
pip install nlpcloudExtraction d’entités (NER)
L’extraction d’entités se fait via spaCy. Tous les modèles spaCy pré-entrainés « larges » sont disponibles, ce qui signifie que 15 langues sont disponibles (pour voir tous les détails sur ces modèles, rendez vous sur le site de spaCy). Vous pouvez aussi uploader les modèles spaCy que vous aurez développés en interne afin de les utiliser en production. Pour cela, rendez-vous dans la section « Custom Models » de votre dashboard :

Maintenant, imaginons que l’on souhaite extraire les entités de la phrase « John Doe is a Go Developer at Google » via le modèle spaCy pré-entrainé pour l’Anglais (« en_core_web_lg »). Voici comment faire :
import nlpcloud
client = nlpcloud.Client("en_core_web_lg", "<votre token API>")
client.entities("John Doe is a Go Developer at Google")Cela vous retournera le contenu de chaque entité extraite ainsi que sa position dans la phrase.
Analyse de sentiments
L’analyse de sentiments se fait via les transformers Hugging Face et le modèle Distilbert Base Uncased Finetuned SST 2 English. Voici un exemple :
import nlpcloud
client = nlpcloud.Client("distilbert-base-uncased-finetuned-sst-2-english", "<votre token API>")
client.sentiment("NLP Cloud proposes an amazing service!")Cela vous dira si le sentiment général se dégageant de ce texte est plutôt positif ou négatif, et avec quelle probabilité.
Classification de texte
L’analyse de sentiments se fait via les transformers Hugging Face et le modèle de Facebook Bart Large MNLI. Voici un exemple :
import nlpcloud
client = nlpcloud.Client("bart-large-mnli", "<votre token API>")
client.classification("""John Doe is a Go Developer at Google.
He has been working there for 10 years and has been
awarded employee of the year.""",
["job", "nature", "space"],
True)Comme vous le voyez, on passe un block de texte que l’on souhaite catégoriser, ainsi que les catégories possibles. Le dernier argument est un booléen qui permet de définir si une seule ou plusieurs catégories à la fois peuvent s’appliquer.
Cela retournera la probabilité de chaque catégorie.
Résumé de texte
Le résumé de texte se fait via les transformers Hugging Face et le modèle de Facebook Bart Large CNN. Voici un exemple :
import nlpcloud
client = nlpcloud.Client("bart-large-cnn", "<votre token API>")
client.summarization("""The tower is 324 metres (1,063 ft) tall,
about the same height as an 81-storey building, and the tallest structure in Paris.
Its base is square, measuring 125 metres (410 ft) on each side. During its construction,
the Eiffel Tower surpassed the Washington Monument to become the tallest man-made
structure in the world, a title it held for 41 years until the Chrysler Building
in New York City was finished in 1930. It was the first structure to reach a
height of 300 metres. Due to the addition of a broadcasting aerial at the top of
the tower in 1957, it is now taller than the Chrysler Building by 5.2 metres (17 ft).
Excluding transmitters, the Eiffel Tower is the second tallest free-standing structure
in France after the Millau Viaduct.")Cela retournera un résumé du texte ci-dessus. Il s’agit d’un résumé « extractif » et non pas « abstractif », ce qui signifie qu’aucune nouvelle phrase n’est générée. En revanche des phrases jugées non-essentielles sont bien entendu supprimées.
Réponse aux questions
Le réponse aux questions se fait via les transformers Hugging Face et le modèle de Deepset Roberta Base Squad 2. Voici un exemple :
import nlpcloud
client = nlpcloud.Client("roberta-base-squad2", "<votre token API>")
client.question("""French president Emmanuel Macron said the country was at war
with an invisible, elusive enemy, and the measures were unprecedented,
but circumstances demanded them.""",
"Who is the French president?")Il s’agit ici de répondre à une question à l’aide d’un contexte.
L’exemple ci-dessus retournera par exemple « Emmanuel Macron ».
Etiquetage morpho-syntaxique (POS tagging)
L’étiquetage morpho-syntaxique (POS tagging) se fait via les mêmes modèles spaCy que pour l’extraction d’entités. Donc par exemple si l’on souhaite utiliser le modèle pré-entrainé anglais, voici comment faire:
import nlpcloud
client = nlpcloud.Client("en_core_web_lg", "<votre token API>")
client.dependencies("John Doe is a Go Developer at Google")Cela retournera, pour chaque token de la phrase, son rôle grammatical, et sa dépendence avec d’autres tokens.
Conclusion
NLPCloud.io est une API pour le NLP facile d’utilisation qui peut vous faire gagner beaucoup de temps lors de la mise en production.
L’équipe prévoit d’ajouter de nouveaux modèles, selon les demandes (traduction, génération de texte…).
A noter aussi que, pour des besoins de performances critiques, des plans avec GPU sont aussi proposés.
En espérant que cet article a été utile à certains ! Si vous avez des questions n’hésitez pas.
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.