
Comment parler de Machine Learning ou même de Deep Learning sans aborder la – fameuse – descente de gradient ? Il y a beaucoup d’articles sur ce sujet bien sur mais bien souvent il faut lire plusieurs afin de bien en comprendre tous les mécanismes. Souvent trop mathématiques ou pas assez, je vais essayer surtout ici d’expliquer son fonctionnement en douceur et pas à pas afin de tenter une démystification du sujet.
Promis pas trop de maths … mais quand même un peu !
Si les formules de mathématiques sont vraiment trop indigestes pour vous, pas de soucis, elles ne sont là que pour expliquer le mécanisme global de la descente de gradient. Vous pouvez donc les passer rapidement … Je dirais que ce qu’il faut retenir de cet article c’est :Le principe itératif de la descente de gradient mais aussi et surtout le vocabulaire associé (epochs, learning rate, MSE, etc.) car vous les retrouverez comme hyperparamètres dans beaucoup d’algorithmes de Machine/Deep Learning.
Qu’est-ce que la Descente de Gradient ?
Pour expliquer ce qu’est la descente de gradient, il faut comprendre tout d’abord pourquoi et d’où vient cette idée. J’aime beaucoup l’image du marcheur en haut d’une montagne qui s’est perdu et qui doit retrouver son village en bas. Mais voilà le relief est escarpé, il y a pleins d’arbres, etc. Bref, comment rentrer ? Bien sur il peut y aller à taton, et tenter une direction, puis au bout d’un moment une autre si pas de succès. Honnêtement ce n’est pas très efficace !
A la place pourquoi ne pas mettre un pied vers la surface la plus basse autour de lui ? puis recommencer comme celà pour chaque pas.
En fait cela revient à sélectionner la direction qui lui est tout simplement donnée par la pente du terrain de manière progressive.
C’est exactement le principe de la Descente de gradient. L’idée est de trouver le minimum d’une fonction mathématique mais sans la résoudre de manière « traditionnelle ». Nous allons à la place mettre en place un algorithme itératif qui va avancer pas à pas pour s’approcher de la solution (et donc trouver notre minimum). Pourquoi ? et bien tout simplement car c’est la seule manière de résoudre certaines équations qui ne sont pas irrésolvables telles quelles.
Une équation ? mais de quoi parle-t-il ?
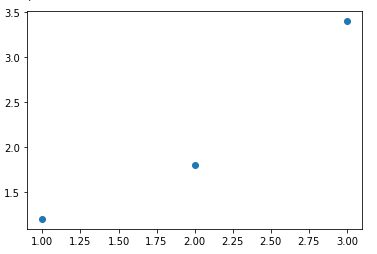
J’ai dit en effet le mot qui fâche : équation. Voyons simplement une équation comme une règle qui régit un comportement ou des observations. Par exemple, nous mesurons chaque minutes le remplissage d’un conteneur et ce pendant 3 minutes. Cela nous fait 3 points, pour chaque point on a en abscisse (x) la minute, et en ordonnée (y) le volume versé.
Voici les 3 points :
- A (1, 1.2)
- B (2, 1.8)
- C (3, 3.4)
Evidemment il n’y a pas de droite (qui passe par ces trois points):
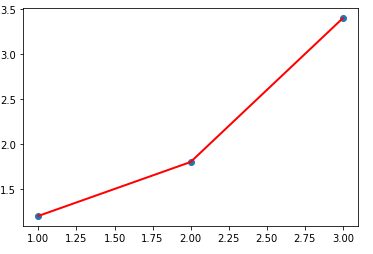
Dans ces conditions, difficile de savoir le volume qui sera versé à la minute 4, puis 5, etc. Pourtant on sait que la loi est une règle linéaire ou du moins elle s’y rapproche. Essayons de trouver cette loi afin de déterminer les valeurs suivantes. C’est ce que l’on appelle une Regression linéaire. Mais ici nous allons surtout aborder le mécanisme de descente de gradient qui nous permettra de trouver la fameuse règle.
L’objectif est donc de trouver les paramètres a et b de l’équation de droite :
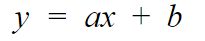
Une fois que l’on aura cette équation de droite il sera extrêmement simple de trouver les valeurs des minutes 5, 6, etc. Mais comment faire ? certainement pas en tâtonnant … ici nous sommes dans un cas simple (1 seul paramètres !) mais parfois il peut y en avoir plusieurs centaines. C’est donc exclu. Nous allons donc, prendre la méthode de l’homme perdu en haut de sa montagne.
Fonction de coût
La fonction de coût permet de mesurer l’erreur qu’il y a entre l’estimation que l’on fait et la valeur réelle (nous sommes dans un mode supervisé). Disons que nous allons avancer pas à pas et qu’à chaque pas que nous faisons nous allons regarder si nous sommes loin de ce que nous attendions: c’est le taux d’erreur. Dans notre cas nous allons utiliser la fonction de coût MSE (erreur quadratique moyenne) qui a pour avantage de pénaliser fortement les grosses erreurs:
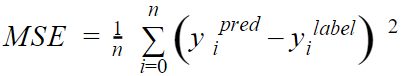
Cette fonction calcule la différence (au carré, d’où la forte pénalisation mentionnée plus haut) de chaque résultat par rapport à l’étiquette attendue. Les valeurs xi et yi sont les valeurs des points (observations) que l’on a déjà relevé.
Remplaçons simplement les valeurs par l’équation de droite que l’on attend (y = ax +b), et l’on obtient:
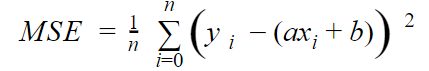
Cette fonction de coût peut aussi être représentée par une parabole (fonction au carré).
Objectif : Trouver la droite la plus proche des points. Cela signifie aussi: Trouver le minimum de cette fonction de coût.
En effet la fonction de coût mesure la somme des distances entre chaque point observé et la droite supposée la meilleure. Dans le schéma ci-dessous, on mesure cette distance par la somme au carré des traits en vert (e1, e2 et e3 car on a 3 observations) :
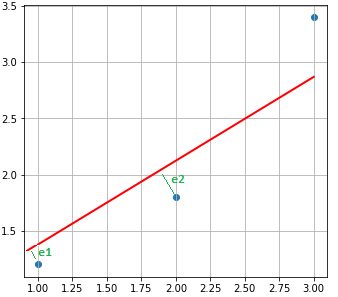
Le résultat doit donc être le plus petit possible.
Variations de la fonction de coût (selon a et b)
Si vos cours de maths de Lycée ne sont pas trop loin, vous devez vous rappeler:
- Une parabole a un seul minimum (bonne nouvelle)
- On mesure la pente d’une courbe avec une dérivée
- On peut dériver une fonction / plusieurs variables (dérivées partielles)
Note: Notre cas est tellement simple qu’on serait tenté de dire que notre fonction atteint son minimum quand sa dérivée est nulle … mais une fois de plus nous sommes dans un cas très (trop) simple qui n’a que deux variables. En réalité il ne serait pas possible de procéder de cette manière.
Développons notre égalité précédente sur la fonction de coût pas à pas:
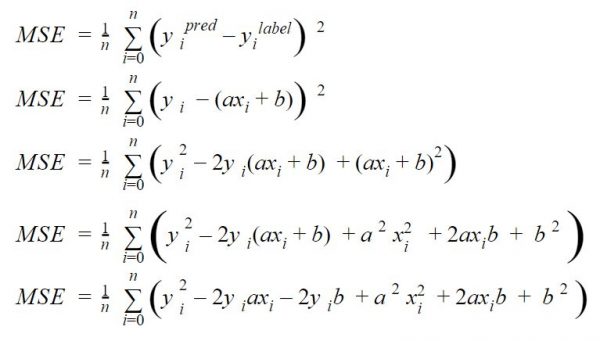
Maintenant regardons ses dérivées (ou gradients) selon les deux variables qui nous interresse: a et b.
Dérivée selon a
En dérivant selon a on regarde les variations de la courbe de coût selon les valeurs de a (c’est une parabole souvenez-vous). Pour trouver a on devra donc trouver le minimum de cette fonction dérivée.
Regardez ce que ça donne pas à pas :
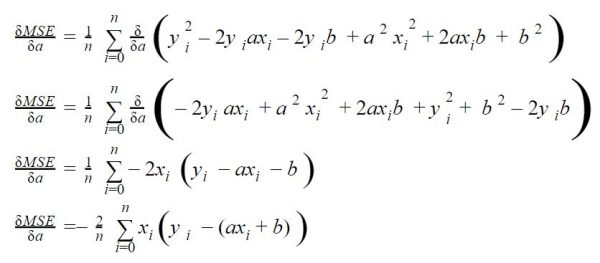
Dérivée selon b
On cherche aussi la valeur de b, dérivons la même équation selon b cette fois:
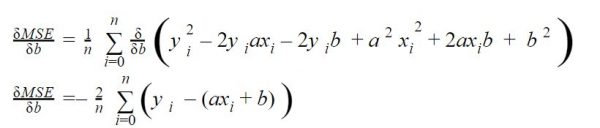
Description de l’algorithme
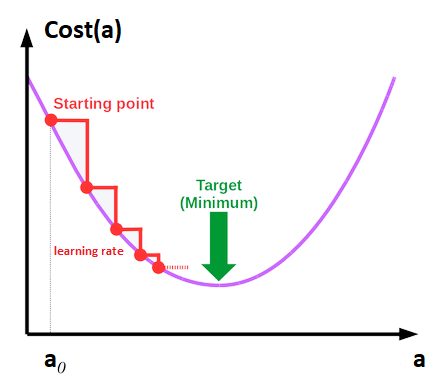
Nous avons les deux fonctions (dérivées) dont nous allons chercher la valeur la plus petite (pour a et b). Pour cela nous allons parcourir ces courbes (l’une et l’autre) et pas à pas comme notre homme en haut de sa montagne.
Chaque pas (epoch) est guidé par le learning rate qui est en quelque sorte la longueur de pas. On a donc plusieurs pas à faire jusqu’à trouver notre minimum (cf. escalier en rouge dans la figure ci-dessous).
Dit autrement, l’idée est donc, pas à pas (ou plutôt epoch après epoch) de s’approcher du minimum par rapport aux dérivées de nos fonctions de coûts que nous avons vu dans le chapitre précédent:

2 remarques :
- Il faut bien commencer par quelque part, aussi on initialisera par des valeurs au hasard a (a0) et b (b0)
- Attention a ne pas choisir un learning rate trop faible sans quoi vous allez mettre beaucoup de temps à arriver au minimum, ou trop grand au risque de le manquer !
Nous allons donc faire du pas à pas, et chaque pas: nous allons calculer les deux gradients (de a et b). Un fois que l’on aura calculé ces gradients nous aurons deux indications :
- Le sens dans lequel nous devons aller (le signe du gradient). En fait c’est assez simple si notre gradient est positif cela signifie que la pente monte vers la droite, on doit donc aller vers la gauche, et vice versa. Pour résumer on doit toujours aller du coté opposé à la pente.
- L’amplitude du pas (qui sera proportionnelle à la valeur du gradient). Plus la pente est forte, plus l’amplitude du pas sera donc grande ! plus on va se rapprocher d’une pente nulle (gradient à zéro), plus cette amplitude va mécaniquement diminuer aussi, de fait.
En Python maintenant …
Voici l’algorithme en Python :
# 3 Observations
X = [1.0, 2.0, 3.0]
y = [1.2, 1.8, 3.4]
def gradient_descent(_X, _y, _learningrate=0.06, _epochs=5):
trace = pd.DataFrame(columns=['a', 'b', 'mse'])
X = np.array(_X)
y = np.array(_y)
a, b = 0.2, 0.5 # Initialisation aléatoire de a et b
mse = []
N = len(X)
for i in range(_epochs):
delta = y - (a*X + b)
# Updating a and b
a = a -_learningrate * (-2 * X.dot(delta).sum() / N) # on retire un gradient à a
b = b -_learningrate * (-2 * delta.sum() / N) # idem pour b
trace = trace.append(pd.DataFrame(data=[[a, b, mean_squared_error(y, (a*X + b))]],
columns=['a', 'b', 'mse'],
index=['epoch ' + str(i+1)]))
return a, b, trace
Remarquez en ligne 13 la boucle qui traduit les pas (epochs). Quant aux lignes 17 et 18 se sont les traductions en Python des dérivées de la fonction de coût que nous avons vu dans les chapitres précédents. Dans ces deux dernières lignes nous avons le calcul de gradient (a et b) qui donne l’amplitude (combiné au learning rate) du pas mais aussi la direction du déplacement. N’oubliez pas qu’on va dans le sens opposé de la valeur du gradient (d’où le signe négatif).
La fonction renvoit les valeurs de a et b calculées mais aussi un DataFrame avec les valeurs qui ont été calculées au fur et à mesure des epochs. Notez aussi que pour le calcul effectif de l’erreur quadratique moyenne j’ai utilisé celle fournie par sklearn : mean_squared_error()
Une petite fonction Python permet enfin de tracer les résultats :
def displayResult(_a, _b, _trace):
plt.figure( figsize=(30,5))
plt.subplot(1, 4, 1)
plt.grid(True)
plt.title("Distribution & line result")
plt.scatter(X,y)
plt.plot([X[0], X[2]], [_a * X[0] + _b, _a * X[2] + _b], 'r-', lw=2)
plt.subplot(1, 4, 2)
plt.title("Iterations (Coeff. a) per epochs")
plt.plot(_trace['a'])
plt.subplot(1, 4, 3)
plt.title("Iterations (Coeff. b) per epochs")
plt.plot(_trace['b'])
plt.subplot(1, 4, 4)
plt.title("MSE")
plt.plot(_trace['mse'])
print (_trace)
Regardons avec 10 epochs ce que cela donne:
a, b, trace = gradient_descent(X, y, _epoch=10) displayResult(a, b, trace)
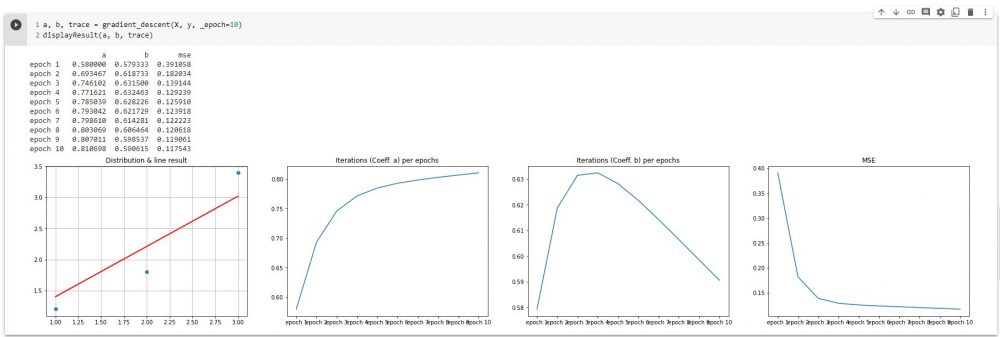
Sur le premier graphe on trouve la droite (en rouge) qui vient d’être trouvée (avec les paramètres a et b).
Le deuxième graphe montre les différentes valeurs de a trouvées par epochs.
Le troisième graphe propose la même chose pour b.
Le dernier graphe nous montre l’évolution de la fonction de coût par epochs. Bonne nouvelle, ce coût diminue régulièrement jusqu’à atteindre un minimum (proche de zéro). On constate que ce minimum est assez vite atteint en réalité (dés les 2ème et 3ème epochs).
Conclusion
Rappelons les grandes étapes de cet algorithme:
- Déterminer la fonction de coût
- Dériver la fonction de coût selon les paramètres à trouver (ici a et b)
- Itérer (pas à pas / epochs – Learning rate) pour trouver le minimum de ces dérivées
Evidemment cette fonction de descente de gradient en Python n’a pas pour vocation d’être réutilisée. L’idée était de montrer à quoi ressemblait ce processus de descente de gradient dans un cas très simple de régression linéaire. Vous pouvez aussi récupérer le code (Jupyter Notebook) qui a été utilisé ici et pourquoi pas changer les hyperparamètres (Learning rate et epochs) pour voir ce qui se passe.
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.
One Reply to “La descente de gradient”