

Quel est le point commun entre un réseau de neurones à convolution, du NLP et des Fake News ?
Aucun à priori … et bien j’en vois d’ores et déjà un: cet article 🙂
Blagues à part je vous propose de créer un réseau de neurones à convolution (CNN) pour faire du NLP, et pour les données je me baserais sur un jeu de données que vous pouvez trouver simplement dans les datasets Kaggle : FrenchFakeNewsDetector (publié par Gilles Hachemes). Vous l’avez compris l’objectif est double: d’une part voir comment on pourra utiliser la technique de convolution avec des vecteurs (1 dimension au lieu d’images à 2+ dimensions) et d’autre part de faire du NLP avec des données en Français.
Récupération du jeu de données / Kaggle
Comme je le disais en introduction nous allons piocher dans un dataset publié dans kaggle. A ce propos vous trouverez aussi le notebook avec le code de cet article dans Kaggle ici.
Note: Le dataset est très simple et pas trop gros, néanmoins je vous conseille si vous utilisez Google Colaboratory ou Kaggle Notebook d’activer les GPU sans quoi la phase d’entrainement sera assez lente.
Ce dataset est composé de 3 colonnes:
- Colonne 1 : media (nous ne l’utiliserons pas)
- Colonne 2: le texte qui contient une nouvelle (vrai ou fausse ???)
- Colonne 3: l’étiquette qui précise si la nouvelle est vraie (0) ou fausse (1)
En terme de volume nous n’avons que 9494 (entrainement et test) ce qui devrait être suffisant pour une classification binaire avec un CNN.
Note : Si vous n’utilisez pas Kaggle Notebook vous allez par contre devoir télécharger les jeux de données d’entrainement et de test manuellement.
Préparation de l’environnement
Pour effectuer cette classification binaire (fake news ou pas ?) nous allons utiliser :
- Python bien sur
- NLTK (NLP)
- TensorFlow 2.x (CNN)
- sklearn
Voilà les imports Python :
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import re
import string
import nltk
from nltk.corpus import stopwords
from nltk import word_tokenize
from nltk.stem.snowball import FrenchStemmer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report,confusion_matrix
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Dense, Input, GlobalMaxPooling1D
from tensorflow.keras.layers import Conv1D, MaxPooling1D, Embedding
from tensorflow.keras.models import Model
from tensorflow.keras.callbacks import EarlyStoppingEn ce qui concerne NLTK il faut importer explicitement les jeux de données en français (pour la tokenisation et les stopwords):
nltk.download('stopwords')
nltk.download('punkt')[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Unzipping corpora/stopwords.zip.
[nltk_data] Downloading package punkt to /root/nltk_data...
[nltk_data] Unzipping tokenizers/punkt.zip.
TrueJeux de données
Tout d’abord il faut récupérer et lire les deux jeux de données afin de les mettre dans un DataFrame Pandas :
dataset_train = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/frfakenews/datafake_train.csv',delimiter=';', encoding='utf-8')
dataset_test = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/frfakenews/datafake_test.csv',delimiter=';', encoding='utf-8')Note: pour cet exemple j’utilise Google colab et j’ai téléchargé puis importé les deux jeux de données dans mon Google Drive.
Je n’aime pas trop les noms de colonnes et on doit aussi retirer la première colonne :
def reformatDataset(df):
df = df.drop(["media"], axis=1)
df = df.rename(columns={'fake': 'label', 'post': 'text'})
return df
dataset_train = reformatDataset(dataset_train)
dataset_test = reformatDataset(dataset_test)Traitement du texte
Retrait de la ponctuation
Les éléments de ponctuation ne présentant aucun interet pour notre modèle, nous allons les retirer. Nous retirerons aussi les nombres et caractères de retour charriot en même temps :
def remove_punct(_str):
_str = re.sub('['+string.punctuation+']', ' ', _str)
_str = re.sub('[\r]', ' ', _str)
_str = re.sub('[\n]', ' ', _str)
_str = re.sub('[«»…"]', ' ', _str)
_str = re.sub('[0-9]', ' ', _str)
return _strRegardons ce que cela donne:
print("Before ->", dataset_train['text'][5])
print("After ->", remove_punct(dataset_train['text'][5]))Before -> Notre-Dame-des-Landes : « La décision prise par l’exécutif est la moins risquée pour lui » 53.Cédric Pietralunga, journaliste au service politique du « Monde », a répondu aux questions des internautes après l’annonce de l’abandon du projet d’aéroport à Notre-Dame-des-Landes..partage facebook twitter
After -> Notre Dame des Landes La décision prise par l’exécutif est la moins risquée pour lui Cédric Pietralunga journaliste au service politique du Monde a répondu aux questions des internautes après l’annonce de l’abandon du projet d’aéroport à Notre Dame des Landes partage facebook twitterPas mal, appliquons cette fonction pour les deux jeux de données :
dataset_train['text'] = dataset_train['text'].apply(remove_punct)
dataset_test['text'] = dataset_test['text'].apply(remove_punct)Retirons les mots inutiles (stop-words)
Pour cela on va utiliser NLTK (et plus particulièrement les mots en français que nous avons téléchargé préalablement):
french_stopwords = set(stopwords.words('french'))
filtre_stopfr = lambda text: [token for token in text if token.lower() not in french_stopwords]On peut créer maintenant une fonction qui retire ces mots mais aussi tokenise et retire les mots de moins de 3 lettres :
# Tokenize, remove stop words and remove the little words (less than 3 characters)
def remove_stop_words_fr(_str):
return [ txt for txt in filtre_stopfr(word_tokenize(_str)) if len(txt)>2]
dataset_train['text'] = dataset_train['text'].apply(remove_stop_words_fr)
dataset_test['text'] = dataset_test['text'].apply(remove_stop_words_fr)Préparation du dataset pour Tensorflow
Préparons les vecteurs (1 dimension) que nous allons passer au CNN :
tokenizer = Tokenizer(num_words=50000, lower=None)
tokenizer.fit_on_texts(dataset_train['text'])
seq_train = tokenizer.texts_to_sequences(dataset_train['text'])
seq_test = tokenizer.texts_to_sequences(dataset_test['text'])Quelques informations :
print("Nb of texts: " , tokenizer.document_count)
#print("Word indexes: " , tokenizer.word_index)
print("Word/token counts: " , len(tokenizer.word_counts))
nb_token = len(tokenizer.word_index)Nb of texts: 6645
Word/token counts: 48712Nous avons presque 50000 token a traiter dans notre matrice.
On complète les vecteurs pour avoir les mêmes dimensions. Pour celà on « complète » le jeu de test (padding) :
ds_train = pad_sequences(seq_train)
train_seq_len = ds_train.shape[1]
ds_test = pad_sequences(seq_test, maxlen=train_seq_len)On créé pour terminer les étiquettes (test et entrainement) :
y_train = dataset_train['label'].astype('int')
y_test = dataset_test['label'].astype('int') Modélisation du réseau de neurones convolutifs (CNN)
Notre réseau est composé de plusieurs couches:
- Entrée (input)
- Embedding
- 1 couche de convolution (32 filtres)
- 1 couche de pooling
- 1 couche de convolution (64 filtres)
- 1 couche de pooling
- 1 couche de convolution (128 filtres)
- 1 couche de Max pooling (vecteur 1 dimension)
- 1 couche Dense (classique) avec une activation de sigmoid car nous faisons une classification binaire.
mon_cnn = tf.keras.Sequential()
mon_cnn.add(Input(shape=(train_seq_len,)))
mon_cnn.add(Embedding(nb_token + 1, 120))
mon_cnn.add(Conv1D(32, 3, activation='relu'))
mon_cnn.add(MaxPooling1D(3))
mon_cnn.add(Conv1D(64, 3, activation='relu'))
mon_cnn.add(MaxPooling1D(3))
mon_cnn.add(Conv1D(128, 3, activation='relu'))
mon_cnn.add(GlobalMaxPooling1D())
mon_cnn.add(Dense(1, activation='sigmoid'))Nous traitons un problème de classification binaire (fake news ou pas). On compile le CNN avec la fonction binary_crossentropy :
mon_cnn.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
mon_cnn.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 4031, 120) 5845560
_________________________________________________________________
conv1d (Conv1D) (None, 4029, 32) 11552
_________________________________________________________________
max_pooling1d (MaxPooling1D) (None, 1343, 32) 0
_________________________________________________________________
conv1d_1 (Conv1D) (None, 1341, 64) 6208
_________________________________________________________________
max_pooling1d_1 (MaxPooling1 (None, 447, 64) 0
_________________________________________________________________
conv1d_2 (Conv1D) (None, 445, 128) 24704
_________________________________________________________________
global_max_pooling1d (Global (None, 128) 0
_________________________________________________________________
dense (Dense) (None, 1) 129
=================================================================
Total params: 5,888,153
Trainable params: 5,888,153
Non-trainable params: 0Entrainement du modèle
Nous allons maintenant entraîner notre modèle.
Mais avant tout définissons une fonction d’early-stopping avec une patience de 2 ce qui signifie que l’entrainement s’arrêtera dés lors que la perte (sur le jeu de test) augmentera deux fois successives. Cela nous permet d’éviter de faire trop d’itérations (epochs) mais aussi et surtout de limiter le sur-entrainement (over-fitting):
early_stop = EarlyStopping(monitor='val_loss', patience=2)
mon_cnn.fit(x=ds_train,
y=y_train,
validation_data=(ds_test, y_test),
epochs=30
,callbacks=[early_stop]
)Epoch 1/30
208/208 [==============================] - 60s 145ms/step - loss: 0.4455 - accuracy: 0.7627 - val_loss: 0.0816 - val_accuracy: 0.9758
Epoch 2/30
208/208 [==============================] - 28s 136ms/step - loss: 0.0331 - accuracy: 0.9886 - val_loss: 0.0831 - val_accuracy: 0.9716
Epoch 3/30
208/208 [==============================] - 28s 135ms/step - loss: 0.0038 - accuracy: 0.9991 - val_loss: 0.0931 - val_accuracy: 0.9677
<tensorflow.python.keras.callbacks.History at 0x7fe0fdbc2610>3 epochs seulement et des scores plutot bons sur le jeu de test (précision: 97%)
Evaluation
Regardons les graphes de pertes et de précision (par epochs) :
losses = pd.DataFrame(mon_cnn.history.history)
losses[['accuracy', 'val_accuracy']].plot()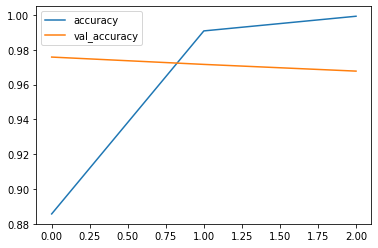
Le graphe de précision :
losses[['loss', 'val_loss']].plot()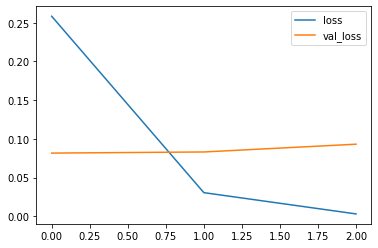
Regardons un peu la précision et le rappel :
from sklearn.metrics import precision_score, recall_score
y_test_pred = np.where(mon_cnn.predict(ds_test) > .5, 1, 0).reshape(1, -1)[0]
print("Precision: {:.2f}%".format(100 * precision_score(y_test, y_test_pred)))
print("Recall: {:.2f}%".format(100 * recall_score(y_test, y_test_pred)))Precision: 96.53%
Recall: 96.95%Nous avons là un bel équilibre …
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.