

DataExplore est un petit utilitaire Open Source qui vous permet de visualiser et même de manipuler vos données. Bien sur, on est assez loin d’outils professionnels et pointus comme Trifacta, Altyrix, ou d’autres mais ce petit utilitaire peut s’avérer très pratique … pour peu que l’on sache l’utiliser correctement. C’est en effet DataExplore est une solution performante mais sa maîtrise nécessite un peu de pratique pour ne pas s’emmêler les pinceaux. Bienvenue dans un monde ou gratuit ne veut pas dire ne rien faire.
En fait et pour ne pas se laisser perturber par l’ergonomie de cet outil disons le simplement afin de le garder en tête : cet outil est outil pour des développeurs qui est en quelque sorte l’interface graphique d’un Dataframe Pandas !
Dans ce cet article nous allons voir comment utiliser cet outil dans ces fonctionnalités de base.
Installation
Pour installer DataExplore, tout d’abord il faut le télécharger sur le site : https://dmnfarrell.github.io/pandastable/
Ensuite suivez les instructions. Selon que vous êtes sur Windows ou Linux (plusieurs distributions sont supportées), tout est expliqué là : https://snapcraft.io/dataexplore
Par exemple sur Ubuntu, toutes les instructions sont ici (en qq lignes) : https://snapcraft.io/install/dataexplore/ubuntu
Découverte de DataExplore
Lancez l’application une fois installée vous devriez avoir cet écran :
L’application se décompose en 3 parties.
- A gauche vous avez les données présentées sous forme d’un tableur
- En haut à droite vous avez la partie visualisation des données (dataviz)
- En bas à droite vous avez la configuration du rendu
Ce qui peut paraitre pertubant et c’est le principe de cet outil c’est que vous allez devoir sélectionnez les données dans la partie tableur. Ce sont ces données qui seront visualisées dans le volet en haut à droite. Attention car la sélection/désélection est rapide, plus délicat encore l’ordre avec lequel vous allez sélectionner les données est important et peut changer totalement le rendu visuel.
Premières manipulations
Pour ce qui est du jeu de données, je vous propose de prendre celles que j’ai récupérée du Covid-19 (Cf. article précédent).
Dans le menu File sélectionnez Import csv.
Ensuite sélectionnez le fichier que vous voulez analyser. Dans notre cas nous prendrons le fichier covid-19 France que j’ai mis dans github : https://github.com/datacorner/python_tutos/blob/master/covid19/data/latest.csv
Suivez et validez toutes les étapes par défaut, à la fin de l’import l’écran suivant doit être proposé (ci-dessous), validez en cliquant sur Import:
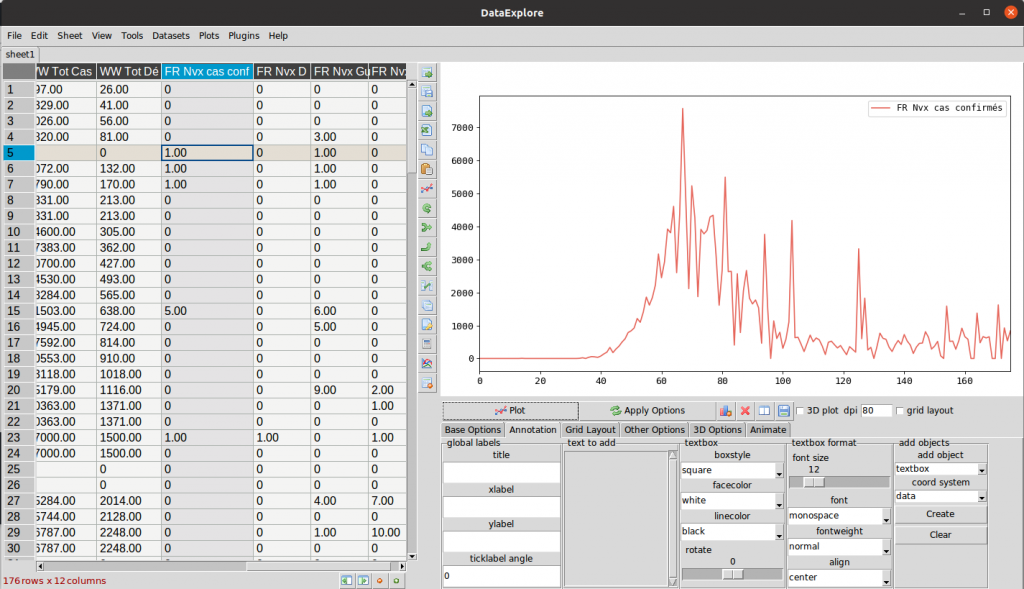
Maintenant cliquez sur une l’entête d’une colonne de données du tableur (à gauche). puis cliquez sur le bouton plot (volet de droite au milieu). DataExplore va afficher la courbe des données que vous avez sélectionnées dans le volet haut de droite. Dans l’exemple ci-dessous j’ai cliqué sur la colonne « FR nvx cas conf » (en surbrillance bleu) :
Allons plus loin …
Ok, en trois clics nous avons eu un graphique intéressant. Mais l’axe des abscisses semble être basé sur des index, et on aimerait plutôt avoir les dates auxquelles les mesures ont été faites non ? Cliquons donc sur l’onglet « Base Options » dans le volet en bas à droite. Désélectionnons ensuite l’option par défaut « use index » qui créé un index automatique et incrémental pour chaque mesure (ligne).
Si on re-clique sur le bouton plot une erreur « Not enough Data … » apparaît. C’est tout à fait normal car maintenant DataExplore attend deux jeux de données (soit deux colonnes). Il faut donc sélectionner dans l’ordre :
- L’entête de la colonne « Date » en premier (c’est important de respecter l’ordre)
- Puis l’entête de la colonne « FR nvx cas conf » en second
Cliquez ensuite sur le bouton Plot :

Dorénavant les deux axes de visualisation prennent bien en compte les deux vecteurs de données choisis !
Ajouter un autre graphe ?
Vous voulez ajouter (empiler) un autre vecteur de données (toujours à partir du même jeu de données) ? rien de plus simple:
- En gardant la touche Control [CTRL] appuyée pour faire une sélection multiple, refaite la même sélection précédente.
- Gardez la touche [CTRL] appuyée et sélectionnez d’autres entêtes de colonnes (par exemple les 4 dernières colonnes du jeu de données …
- Cliquez sur Plot:
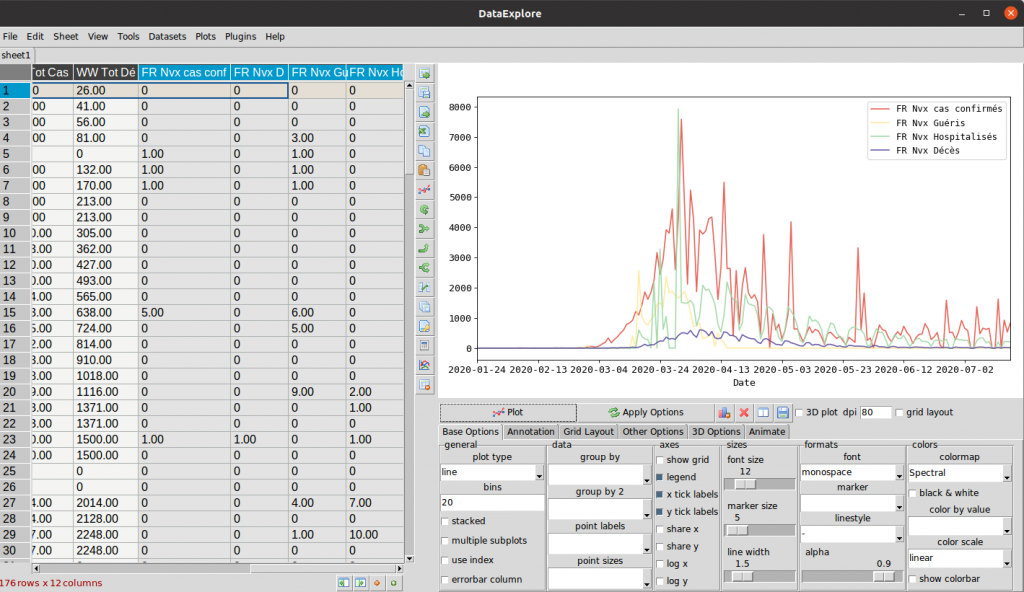
Le graphe de visualisation ajoute alors automatiquement les vecteurs dans la viz comme ci-dessus.
D’autres options ?
Bien sur l’outil dispose de multiples options de visualisation :
- « plot type » permet de changer le mode de visualisation : graphe à barre, ligne, points, etc.
- « group type » permet de gérer des regroupements de données jusque 2 niveaux
- « show grid » permet d’afficher la grille
- « legend » permet d’afficher la légende
- On peut préciser un titre et plein d’autres annotations dans l’onglet « Annotation«
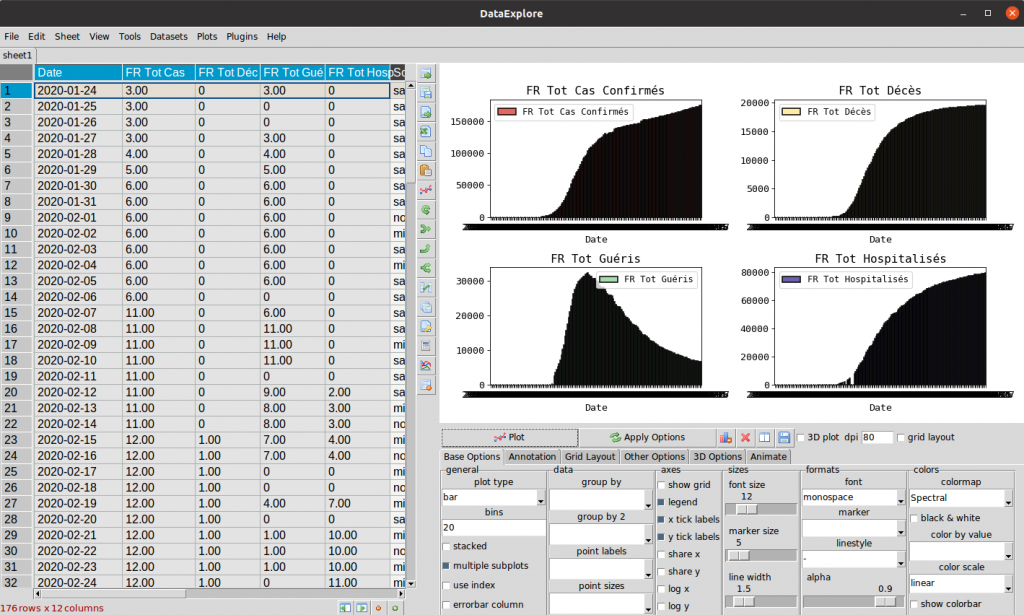
Vous voulez avoir plusieurs viz mais pas de manière superposée ? pas de soucis :
- Dans l’onglet « base options » choisissez « multiple subplots«
- Puis sélectionnez (comme précédemment 4 vecteurs via 4 entêtes de colonnes)
- Cliquez sur Plot …
Conclusion
Nous avons vu dans ce post les manipulations simple de cet outil.
DataExplore est un outil vraiment intéressant comme je le disais en introduction mais qui nécessite une certaine habitude dans son utilisation. Si vous avez essayé de l’utiliser vous vous êtes rendu compte que l’outil perd vite la sélection d’une colonne (à cause d’un clic malencontreux) et du coup parfois on peu se mélanger les pinceaux … A part ces quelques soucis de manipulation, c’est un outil qui peut s’avérer très pratique.
Pour conclure cette première partie, je trouve que c’est un outil à essayer (d’autant que ça ne vous en coûtera que du temps) ! D’ailleurs, si vous n’êtes pas convaincu vous pouvez aussi attendre la seconde partie de cet article dans le quel je traiterai notamment ses capacités pour manipuler plusieurs jeux de données, effectuer des filtrages, des fonctions, etc.
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.