
Accéder à la bonne information, au bon moment et au bon format a toujours été, et reste toujours un enjeu majeur dans les entreprises. Mais voilà, les parcs applicatifs bougent, changent et évoluent vite … de plus en plus vite ! Trop souvent même pour les services informatiques qui n’arrivent plus à suivre le rythme des demandes de changements réclamées par les métiers. Les projets de type décisionnel et transactionnel doivent donc faire face à des demandes continues de changement rapide afin d’être utilisés de manière efficace et fiable, et donc de gagner en crédibilité.
L’enjeu de l’accès aux données

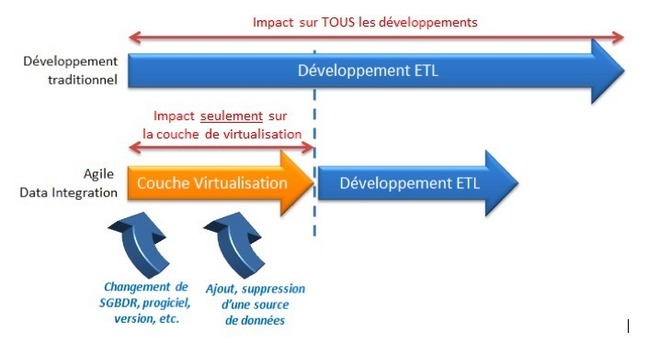
Les impacts projet
Accélérer la phase d’intégration peut se matérialiser par deux axes.

Simplifier la couche d’accès
Impliquer MOE et MOA dans un processus collaboratif
Pourquoi faire de l’Agile Data Integration ?
Pour résumer faire de « l’Agile Data Integration » doit passer par la mise en place d’une couche intermédiaire d’accès aux données. Cette couche propose en fait des services d’accès aux données simple et optimisés qui surtout peuvent être mis en place par la MOA et la MOE conjointement.La solution Informatica Data Services est une réponse simple et complète à toutes les problématiques de type virtualisation de données, mais va aussi bien au-delà en proposant une flexibilité et des possibilités d’optimisation sans équivalent sur le marché. Vous pourrez ainsi créer de manière naturelle ce fameux modèle logique en y apportant toute la richesse des possibilités d’intégration et de qualité de données. Ajoutez à cela une interface dédiée aux MOA pour manipuler simplement et créer/modifier des tables virtuelles sans avoir besoin de connaissances SQL ou autre langage, vous aurez une solution de type Agile qui vous apportera un bénéfice significatif dans la réalisation et la durée de vie de vos projets d’intégration.

Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.