

Principe de XGBoost
Si vous ne connaissiez pas cet algorithme, il est temps d’y remédier car c’est une véritable star des compétitions de Machine Learning. Pour faire simple XGBoost (comme eXtreme Gradient Boosting) est une implémentation open source optimisée de l’algorithme d’arbres de boosting de gradient.
Mais qu’est-ce que le Boosting de Gradient ?
Le Boosting de Gradient est un algorithme d’apprentissage supervisé dont le principe et de combiner les résultats d’un ensemble de modèles plus simple et plus faibles afin de fournir une meilleur prédiction.
On parle d’ailleurs de méthode d’agrégation de modèles. L’idée est donc simple : au lieu d’utiliser un seul modèle, l’algorithme va en utiliser plusieurs qui serons ensuite combinés pour obtenir un seul résultat.
C’est avant tout une approche pragmatique qui permet donc de gérer des problèmes de régression comme de classification.
Pour décrire succinctement le principe, le l’algorithme travaille de manière séquentielle. Contrairement par exemple au Random Forest. cete façon de faire va le rendre plus lent bien sur mais il va surtout permettre à l’algorithme de s’améliorer par capitalisation par rapport aux exécutions précédentes. Il commence donc par construire un premier modèle qu’il va bien sur évaluer (on est bien sur de l’apprentissage supervisé). A partir de cette première évaluation, chaque individu va être alors pondérée en fonction de la performance de la prédiction. Etc.
XGBoost se comporte donc remarquablement dans les compétitions d’apprentissage automatique(Machine Learning), mais pas seulement grâce à son principe d’auto-amélioration séquentielle …
XGBoost inclut en effet un grand nombre d’hyperparamètres qui peuvent être modifiés et réglés à des fins d’amélioration !
Cette grande flexibilité fait donc de XGBoost un choix solide qui vous faut absolument essayer 😉
XGBoost par la pratique
Autre bonne (ou mauvaise) nouvelle : XGBoost ne fait pas partie de Scikit-Learn … mais s’intègre par contre parfaitement bien avec. Les exemples ci-dessous utilisent cette intégration, mais sachez que bien sur vous pouvez utiliser XGBoost sans avoir Scikit-Learn.
Nous allons récupérer et travailler sur notre bon vieux jeu de données du Titanic. Vous vous souvenez ? il s’agit de prédire si un passager va survivre … c’est donc un problème de classification binaire. Nous utiliserons donc évidemment XGBoost comme classifier.
from xgboost import XGBClassifier
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
import xgboost as xgb
train = pd.read_csv("../titanic/data/train.csv")
test = pd.read_csv("../titanic/data/test.csv")Évidemment on ne coupera pas à un peu de préparation de données, ce n’est pas l’objectif de cet article aussi on fera très simple ici. Voici une petite fonction Python qui préparera les jeux d’entraînement et de test :
def dataprep(data):
sexe = pd.get_dummies(data['Sex'], prefix='sex')
cabin = pd.get_dummies(data['Cabin'].fillna('X').str[0], prefix='Cabin')
# Age
age = data['Age'].fillna(data['Age'].mean())
emb = pd.get_dummies(data['Embarked'], prefix='emb')
# Prix du billet / Attention une donnée de test n'a pas de Prix !
faresc = pd.DataFrame(MinMaxScaler().fit_transform(data[['Fare']].fillna(0)), columns = ['Prix'])
# Classe
pc = pd.DataFrame(MinMaxScaler().fit_transform(data[['Pclass']]), columns = ['Classe'])
dp = data[['SibSp']].join(pc).join(sexe).join(emb).join(faresc).join(cabin).join(age)
return dpPréparons donc ces datasets et récupérons pour le jeu d’entraînement les étiquettes (labels) :
Xtrain = dataprep(train)
Xtest = dataprep(test)
y = train.SurvivedEntraînons maintenant notre algorithme XGBoost. Pour les hyper-paramètres nous prendrons ceux par défaut.
boost = XGBClassifier()
boost.fit(Xtrain, y)
p_boost = boost.predict(Xtrain)
print ("Score Train -->", round(boost.score(Xtrain, y) *100,2), " %")Hyper-Paramètres
Bien sur XGBoost est paramétrable, retrouvez la liste des hyper-paramètres sur le site directement https://xgboost.readthedocs.io/en/latest/parameter.html
Attention il va falloir gérer ces paramètres sur 3 niveaux :
- Les paramètres généraux
- Les paramètres du booster choisit (ceux ci dépendent des choix précédents)
- Les paramètres d’apprentissage (régression et classification n’auront pas ici les mêmes entrées).
Voici un exemple d’affectation de paramètres à l’instanciation du classifier:
param = {}
param['booster'] = 'gbtree'
param['objective'] = 'binary:logistic'
param["eval_metric"] = "error"
param['eta'] = 0.3
param['gamma'] = 0
param['max_depth'] = 6
param['min_child_weight']=1
param['max_delta_step'] = 0
param['subsample']= 1
param['colsample_bytree']=1
param['silent'] = 1
param['seed'] = 0
param['base_score'] = 0.5
clf = xgb.XGBClassifier(params)Evaluation
Outre les métriques que nous avons abordés dans l’évaluation d’algorithmes de classification, la librairie XGBoost founit quelques métriques intéressantes.
Graphique présentant les champs par degré d’importance :
xgb.plot_importance(boost)
Graphique présentant le résultat :
xgb.to_graphviz(boost, num_trees=2)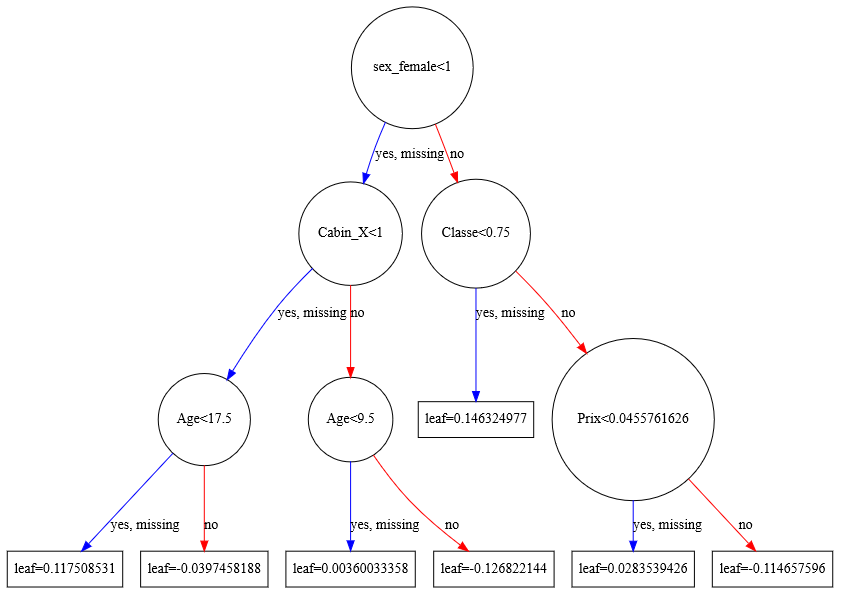
Sauvegarde et chargement de modèle
La librairie inclut aussi la possibilité de sauvegarder et recharger un modèle:
Sauvegarde d’un modèle entrainé :
boost._Booster.save_model('titanic.xbmodel')Chargement d’un modèle sauvegardé :
boost = xgb.Booster({'nthread': 4}) boost.load_model('titanic.xbmodel')Et sans Scikit-Learn ?
Comme je le disais plus haut on peut tout à fait utiliser XGBoost indépendamment de Scikit-Learn, voici les quelques différences :
import xgboost as xgb
dtrain = xgb.DMatrix(x_train,y_train)
param = {'boost':'linear',
'learnin_rate':0.1,
'max_depth': 5,
'objective': 'reg:linear',
'eval_metric':'rmse'}
num_round = 100
bst = xgb.train(param, train, num_round)
preds = bst.predict(dtest)Attention
Comme pour les autres algorithmes basés sur des arbres … attention à l’overfitting (sur apprentissage). Pour cela on reviendra aux bonnes vieilles recettes : limiter la taille des arbres (sans jeu de mots) mais aussi de construire et travailler sur des échantillons à partir du jeu de données initial.
Dans la même famille des algorithmes de boosting gradient, je vous invite aussi à lire mon article sur le CatBoost.
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.
Très bonne explication ! Sur Kaggle beaucoup remportent des compétitions avec cet algorithme.
Votre article est simplement excellent, ce qui ce conçoit aisément s’énonce clairement et c’est le cas ici. Merci Benoit CAYLA.
Bonjour,
J’ai apprécié ton blog et tes vidéos sur YouTube
Je commence en septembre (2022) prochain mon M2 ML for AI à l’université Lyon 2
Je m’intéresse tout ce qui est Deep learning, NLP, les modèle pré-entrainés (BERT, GPT,….), et aussi les technos de gestion de Big data.
Je m’accroche ici pour faire de la veille et découvrir plein de choses
Bien à vous
Bien cordialement
Bjr, j’ai suivi avec attention cette vidéo YouTube qui vraiment formidable.
cependant j’ai de souci a entrainer sur XGBoost un ensemble de donnée pour obtenir en sortie une modèle de prédiction supérieur