

Dans un article précédent (cliquez ici) nous avons vu comment installer et utiliser tesseract dans des exemples simples. Malheureusement si Tesseract reste une bonne solution (gratuite qui plus est) elle a ses limites. Certaines peuvent être remédiés via certaines configurations ou pré-traitement, d’autres non !
Limites de Tesseract
Voici quelques limitations de Tesseract :
- Évidemment Tesseract n’est pas aussi précis que certaines solutions commerciales (de type ABBYY par exemple)
- Malheureusement Tesseract n’est pas capable de reconnaître l’écriture manuscrite.
- Tesseract ne fonctionne pas vraiment bien avec les images qui ont subit certaines modifications (arrière-plan complexe ou brouillé, lignes, occlusion partielle, déformation, etc.)
- Il peut parfois renvoyer du charabia (faux positifs)
- Il est sensible à la langue précisée en argument. En gros, Si un document contient des langues autres que celles indiquées dans les arguments -l LANG, les résultats peuvent être vraiment très mauvais !
- tesseract analyse dans l’ordre de lecture naturel des documents, ce qui n’est pas toujours la bonne méthode. Par exemple, il peut ne pas reconnaître qu’un document contient plusieurs colonnes et peut essayer de joindre le texte de ces colonnes comme une seule ligne.
- Il a du mal à interpréter des numérisations de mauvaise qualité.
- Il n’expose pas d’informations/métadonnées sur le texte (comme la police).
Nous allons voir dans cet article comment s’affranchir au mieux de certaines de ces limites.
Visualisons déjà ce qui est reconnu par Tesseract
Pour commencer il peut être très utile de pouvoir voir ce que tesseract a interprété. Que diriez-vous d’afficher l’image avec en surlignage les zones détectées et interprétées comme du texte ?
Pour cela nous allons utiliser une librairie très puissante et très utilisées dans la « Vision par Ordinateur » : OpenCV.
try:
from PIL import Image
except ImportError:
import Image
import pytesseract
from pytesseract import Output
import cv2
simage = r'/[Path to image...]/image_2.png'
img = cv2.imread(simage)
d = pytesseract.image_to_data(img, output_type=Output.DICT)
NbBoites = len(d['level'])
print ("Nombre de boites: " + str(NbBoites))
for i in range(NbBoites):
# Récupère les coordonnées de chaque boite
(x, y, w, h) = (d['left'][i], d['top'][i], d['width'][i], d['height'][i])
# Affiche un rectangle
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()Cette petite routine va afficher l’image originale. En se basant sur les cadres de texte détectés par Tesseract (récupéré via la méthode image_to_data), on va lui superposer des cadres verts sur les mots détectés. Un nouvel écran s’affiche :

Note: Pour fermer l’écran appuyez juste sur une touche du clavier. si vous voulez afficher la fenetre pendant un temps limité (en ms) changez la valeur de cv2.waitKey([temps en ms]).
Cette façon de visualiser les résultats de Tesseract est très pratique et pour être utiliser pour mieux comprendre le comportement de cet outil.
On peut aussi utiliser la librairie Python matplotlib pour visualiser les résultats :
from matplotlib import pyplot as plt
plt.imshow(img)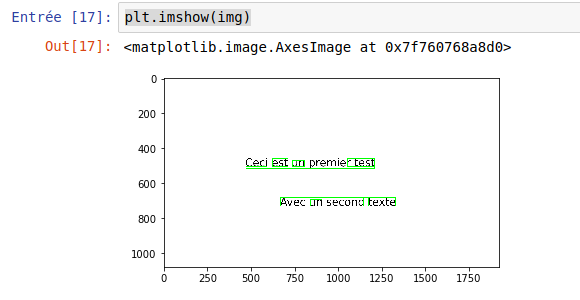
Note : Retrouvez les sources complets sur Github.
Modification de l’image source (pre-processing)
C’est l’un des principal défaut de Tesseract: si l’image n’est pas vraiment parfaite, celle-ci nécessitera certainement un pré-traitement avant de pouvoir la soumettre à l’OCR. Heureusement nous avons plusieurs librairies magiques à notre disposition, dont OpenCV que nous avons déjà utilisé au préalable.
Sur internet j’ai trouvé quelques petites fonctions bien utiles qui encapsulent cette librairie :
# grayscale
def grayscale(image):
return cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# noise removal
def remove_noise(image):
return cv2.medianBlur(image,5)
# thresholding
def thresholding(image):
return cv2.threshold(image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)[1]
# dilation
def dilate(image):
kernel = np.ones((5,5),np.uint8)
return cv2.dilate(image, kernel, iterations = 1)
# erosion
def erode(image):
kernel = np.ones((5,5),np.uint8)
return cv2.erode(image, kernel, iterations = 1)
# opening - erosion followed by dilation
def opening(image):
kernel = np.ones((5,5),np.uint8)
return cv2.morphologyEx(image, cv2.MORPH_OPEN, kernel)
# canny edge detection
def canny(image):
return cv2.Canny(image, 100, 200)
# skew correction
def deskew(image):
coords = np.column_stack(np.where(image > 0))
angle = cv2.minAreaRect(coords)[-1]
if angle < -45:
angle = -(90 + angle)
else:
angle = -angle
(h, w) = image.shape[:2]
center = (w // 2, h // 2)
M = cv2.getRotationMatrix2D(center, angle, 1.0)
rotated = cv2.warpAffine(image, M, (w, h), flags=cv2.INTER_CUBIC, borderMode=cv2.BORDER_REPLICATE)
return rotated
# template matching
def match_template(image, template):
return cv2.matchTemplate(image, template, cv2.TM_CCOEFF_NORMED)Nous allons maintenant les utiliser pour retravailler nos images qui ont quelques défauts bien sur :

Si nous utilisons tesseract directement sur cette image, nous obtenons un résultat plutôt faux:
simage = r'/home/benoit/git/python_tutos/tesseract/image_4.png'
image_original = cv2.imread(simage)
print(pytesseract.image_to_string(image_original, lang='fra'))
plt.imshow(image_original,'gray')jaur ceci est un testEn retirant les « bruits » de l’image on a quelque chose de bien mieux :
retouche3 = remove_noise(image_original)
print(pytesseract.image_to_string(retouche3, lang='fra'))
plt.imshow(retouche3)Faisons un autre essai avec une image encore plus brouillée (notament en rajoutant un trait transversal sur le texte) :

Ce qui est intéressant ici c’est que tesseract ne détecte rien du tout : aucun texte !!!
Essayons de réduire le bruit sur l’image comme précédemment :
retouche3 = remove_noise(image_original)
print(pytesseract.image_to_string(retouche3, lang='fra'))
plt.imshow(retouche3)Nous obtenons un résultat certes mieux mais incorrect :
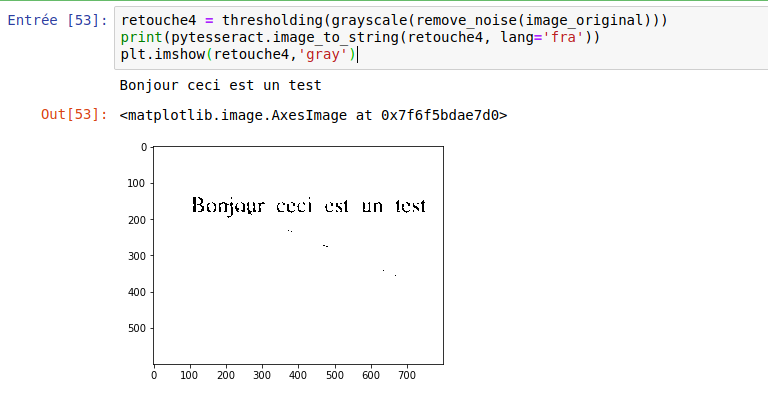
Bonjour cect est un testSi maintenant on joue sur l’atténuation et la mise en niveau de gris :
retouche4 = thresholding(grayscale(remove_noise(image_original)))
print(pytesseract.image_to_string(retouche4, lang='fra'))
plt.imshow(retouche4,'gray')Le résultat devient alors correct …
Et si vous avez des fichiers pdf à traiter ?
C’est en effet un cas bien réel. Les fichiers à traiter ne sont pas au format image (png, jpg, etc.). Bien souvent vous avez des fichiers de type pdf à traiter, et manque de chance Tesseract ne sait pas directement les traiter ! encore une fois nous allons devoir faire un pré-traitement ou plus précisément une conversion afin de convertir notre fichier pdf dans un format image que tesseract pourra gérer. Attention car une légère nuance va s’ajouter : la pagination. En effet un pdf est bien souvent sur plusieurs pages alors qu’une image elle non. Il faudra donc bien prendre en compte cette nuance.
Heureusement Python possède un écosystème de librairie vraiment incroyable. Pour ce qui est de la conversion PDF -> PNG/JPG je vous suggère d’utiliser pyPI/pdf2image.
Pour celà l’installation se fait en deux étapes :
installation de la librairie Python :
pip install pdf2imageInstallation de l’utilitaire de conversion (binaire). sur Linux c’est plutot simple (Ubuntu) :
sudo apt-get install poppler-utilsSur windows c’est un peu plus complexe:
- Téléchargez tout d’abord le dernier binaire sur le site de Poppler http://blog.alivate.com.au/poppler-windows/
- Dézippez les fichiers avec les répertoires
- AJoutez une entrée dans votre PATH (plus particulièrement le répertoire bin dézippé).
Cela fait vous pouvez utiliser la librairie et en quelques lignes convertir votre fichier PDF :
from pdf2image import convert_from_path, convert_from_bytes
try:
from PIL import Image
except ImportError:
import Image
import pytesseract
from pytesseract import Output
images = convert_from_path('Facture.pdf')
print ("Nombre de pages: " + str(len(images)))
for i in range (len(images)):
print ("Page N°" + str(i+1) + "\n")
print(pytesseract.image_to_string(images[i]))Cette portion de code va effectuer une interprétation de chaque page de votre pdf.
Conclusion
Comme nous l’avons vu en introduction si Tesseract est un outil performant et surtout gratuit, son défaut est qu’il ne peut pas tout gérer de manière simple. Comme bien souvent pour les projets Open Source et gratuit on peut faire beaucoup de choses mais moyennant des efforts réels d’intégration. Restent néanmoins plusieurs limites qui peuvent devenir vite contraignantes comme l’interprétation d’écriture manuscrite. Mais ceci est une autre histoire et pour cela il existe bien entendu d’autres solutions que nous tâcherons d’aborder ultérieurement.
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.
5 Replies to “Utilisation avancée de Tesseract avec Python”