

L’objectif de cet article est de montrer au travers d’un cas concret et français la méthode pour effectuer une analyse de sentiments avec Python.
Objectif du cas d’usage
Pour cet article nous allons analyser des critiques de films en Français. Etant donné qu’il n’est pas simple de trouver des jeux de données de ce type (en Français je veux dire), je vous propose d’aller chercher des données directement à leur source, sur allociné par exemple.
Voici donc les étapes que nous allons parcourir ensemble :
- Récupération des données
- Préparation des données (normalement cette phase est bien sur précédée d’une phase de profiling mais nous la passerons pour aller plus vite).
- Préparation du modèle et des jeux de données (entrainement & test)
- Modélisation
- Résultat
Voici les grandes étapes que nous allons parcourir, alors allons-y !
Le problème à traiter
Comme je vous l’ai dit nous allons récupérer les données directement sur le site d’Allociné. En d’autre mots nous allons scraper les pages qui nous interressent sur ce site à savoir les critiques des personnes pour les films Inception et Bigfoot.
Note : Les pages de critiques ont la même structure, ce sera donc le même travail quel que soit le film.
Si vous allez sur la page des critiques vous verrez que seules deux type d’information nous intéresse : la note du spectateur ainsi que son commentaire.
Pourquoi la note ? parce que nous allons entraîner un modèle de type supervisé et que donc la note va nous aider dans cette classification.
Nous sommes donc bel et bien dans un problème de classification. Nous pourrions bien sur essayer de donner la note en fonction du commentaire mais afin de commencer simplement nous allons réduire le problème à une classification binaire. Pour faire simple, en lisant le commentaire, le spectateur a-t-il été satisfait ou non ? pour cela nous considérerons qu’une note au dessus de 3 est considérée comme satisfaisante. En dessous l’avis est négatif.
- Note > 3 : Avis positif
- Note <= 3 Avis négatif
Scrapons les données d’avis de spectacteur
Nous ne devons « scraper » que deux zones (en rouge ci-dessous) :
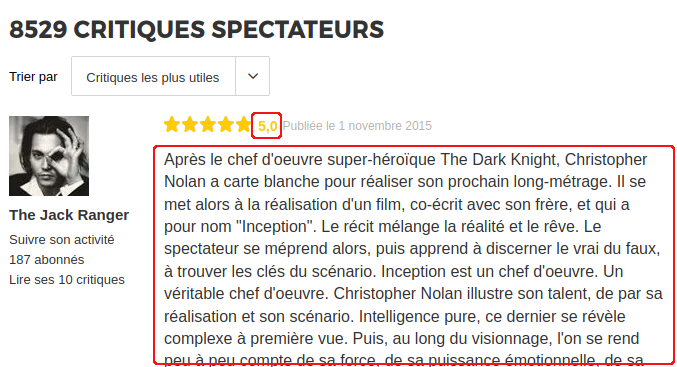
Ces deux zones sont tagguées en HTML avec les balises :
- Note : ‘//span[@class= »stareval-note »]’
- Description : ‘//div[@class= »content-txt review-card-content »]’
La méthode pour scraper cette page est décrite dans l’article suivant. Voici le résultat :
import requests
import lxml.html as lh
import pandas as pd
url = 'http://www.allocine.fr/film/fichefilm-143692/critiques/spectateurs/'
uri_pages = '?page='
nbPages = 400
tags = ['//span[@class="stareval-note"]', \
'//div[@class="content-txt review-card-content"]' ]
cols = ['Note', 'Description' ]
page = requests.get(url)
doc = lh.fromstring(page.content)
def getPage(url):
page = requests.get(url)
doc = lh.fromstring(page.content)
# Get the Web data via XPath
content = []
for i in range(len(tags)):
content.append(doc.xpath(tags[i]))
# Gather the data into a Pandas DataFrame array
df_liste = []
for j in range(len(tags)):
tmp = pd.DataFrame([content[j][i].text_content().strip() for i in range(len(content[i]))], columns=[cols[j]])
tmp['key'] = tmp.index
df_liste.append(tmp)
# Build the unique Dataframe with one tag (xpath) content per column
liste = df_liste[0]
for j in range(len(tags)-1):
liste = liste.join(df_liste[j+1], on='key', how='left', lsuffix='_l', rsuffix='_r')
liste['key'] = liste.index
del liste['key_l']
del liste['key_r']
return liste
def getPages(_nbPages, _url):
liste_finale = pd.DataFrame()
for i in range (_nbPages):
liste = getPage(_url + uri_pages + str(i+1))
liste_finale = pd.concat([liste_finale, liste], ignore_index=True)
return liste_finale
liste_totale = getPages(nbPages, url)
liste_totale.to_csv('../../datasources/films/allocine_inception_avis.csv', index=False, quoting=csv.QUOTE_NONNUMERIC)Il suffit de reproduire ce code (en changeant bien sur l’URL et le nombre de pages) aux films désirés et le tour et joué. Normalement vous devriez maintenant dispose d’au moins deux fichier d’avis de spectateurs qui auront cette forme :

Préparation des données
Maintenant que nous avons nos jeux de données, il va falloir les préparer afin de pouvoir modéliser notre analyse de sentiments.
Pour cela nous allons faire appel à plusieurs techniques :
- Des expressions régulières pour retirer les bruits (ponctuation, etc.) des commentaires.
- Du NLP pour tokeniser et réduire le corpus de chaque commentaire (afin par exemple de ne garder que les mots importants via les stopwords)
- Des sacs de mots afin de « transformer » nos mots en nombres qui pourront alors être exploités dans un algorithme de Machine learning tel qu’une regression logistique par exemple.
Note: pour plus de détails sur ces techniques n’hésitez pas à vous reporter aux articles qui s’y réfèrent (Cf. liens ci-dessus).
Retirer les bruits des commentaires
Pour cela nous allons utiliser des expressions régulières et retirer les éléments de ponctuation mais aussi les retours chariots et autres caractères inutiles à notre analyse.
REMPLACE_SANS_ESPACE = re.compile("[;:!\'?,\"()\[\]]")
REMPLACE_AVEC_ESPACE = re.compile("()|(\-)|(\/)|[.]")
PUR_NOMBRE = re.compile("[0-9]")
def setClassBin(i):
if (float(i.replace(',', '.')) > 3):
return 1
else:
return 0
def preprocess(txt):
txt = [PUR_NOMBRE.sub("", (str(line)).lower()) for line in txt] # retire les nombres (comme les années)
txt = [line.replace('\n', ' ') for line in txt] # Retire les \n (retours chariots)
txt = [REMPLACE_SANS_ESPACE.sub("", line.lower()) for line in txt]
txt = [REMPLACE_AVEC_ESPACE.sub(" ", line) for line in txt]
return txtSimplification des données de commentaire
Pour commencer nous allons utiliser les stopwords que nous avons vu quand nous avons abordé le NLP (SpaCy et NLTK):
X['Description'] = pd.DataFrame(preprocess(X['Description']))
french_stopwords = set(stopwords.words('french'))
filtre_stopfr = lambda text: [token for token in text if token.lower() not in french_stopwords]
X['Description'] = [' '.join(filtre_stopfr(word_tokenize(item))) for item in X['Description']]Une fois initialisés les stopwords en français nous créons une fonction qui va filter les commentaires avec cette liste (composée du commentaire « tokenisé » en mots).
Voilà nos commentaires sont maintenant filtrés à leur essentiel.
Préparation des libellés
Il y a assez peu de chose à faire de ce coté là, mais n’oubliez pas que nous récupérions des notes de 1 à 5 et non une classe binaire. Il nous faut donc convertir nos notes :
def setClassBin(i):
if (float(i.replace(',', '.')) > 3):
return 1
else:
return 0
yList = [setClassBin(x) for x in X.Note]
y = pd.DataFrame(yList)
X = X.drop('Note', axis=1)Note: N’oublions pas à la fin de retirer la note du jeu de caractéristiques.
Finalisons nos jeux de données
Nos données sont presque prêtes, à ceci près que nous n’avons pas encore convertit nos commentaires en nombre et que nous n’avons pas encore mixés nos jeux de données. Créons d’abord nos jeux de données et concaténons nos données de Bigfoot et Inception :
Xtrain, ytrain = prepare_dataset(train)
Xtest, ytest = prepare_dataset(test)
Xf = pd.concat([Xtrain, Xtest])
yf = pd.concat([ytrain, ytest])Ensuite nous allons vectoriser nos mots (technique des sacs de mots) :
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer(binary=True)
cv.fit(Xf["Description"])
Xf_onehot = cv.transform(Xf["Description"])
Xtest_onehot = cv.transform(Xtest["Description"])
pd.DataFrame(Xf_onehot.toarray())Vous devriez avoir maintenant une belle matrice avec beaucoup de colonnes (qui correspond au nombre de mots du corpus) :
Entraînement du modèle
Nos données sont prêtes, nous allons pour ce premier exercice utiliser un algorithme de Regression Logistique.
Notre première étape consiste à trouver le meilleur hypermaramètre c pour cet algorithme. On va en essayer quelque uns pour voir le meilleur :
X_train, X_val, y_train, y_val = train_test_split(Xf_onehot, yf, train_size = 0.75)
for c in [0.01, 0.05, 0.25, 0.5, 1]:
lr = LogisticRegression(C=c)
lr.fit(X_train, y_train)
print ("Précision pour C=%s: %s" % (c, accuracy_score(y_val, lr.predict(X_val))))Précision pour C=0.01: 0.8468708388814914
Précision pour C=0.05: 0.8901464713715047
Précision pour C=0.25: 0.9027962716378163
Précision pour C=0.5: 0.9014647137150466
Précision pour C=1: 0.8981358189081226Il semblerait que la meilleure valeur de c soit 0.25 dans notre cas.
Entraînons le modèle maintenant, et regardons sa précision par rapport au libellés connus :
final_model = LogisticRegression(C=0.25)
final_model.fit(Xf_onehot, yf)
print ("Précision: %s" % accuracy_score(ytest, final_model.predict(Xtest_onehot)))Précision: 0.8571428571428571Sans grandes optimisations nous avons un petit 85%.
Conclusion
L’objectif de cet article était de montrer un exemple d’implémentation de A à Z d’un algorithme d’analyse de sentiments. Sans grands efforts nous avons obtenus un score de 85%, ce qui n’est pas si mal. Bien sur on pourrait changer ou optimiser l’algorithme (utiliser un algorithme de Bayes ou un SVM par exemple), mais c’est surtout dans le travail sur le corpus que l’on pourrait considérablement améliorer la performance de notre modèle. C’est un travail de fourmi bien sur et d’ajustements sans cesse qui fait que ce type de problème est assez complexe à maintenir jusqu’à avoir suffisamment de données d’apprentissage.
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.
Bonjour M. Cayla,
je ne comprends pas bien le lien du résultat avec l’objectif. Je ne comprends pas non plus l’objectif du reste. A quoi vous sert l’algorithme si de toutes façons vous avez une note qui accompagne tous les textes ? Je ne comprends pas non plus désolé ce que permet de conclure la précision à 85%. C’est dommage le sujet a l’air super intéressant
Bonjour Michael,
Déjà ravis de voir que le sujet intéresse un si illustre joueur de basket 🙂
Plaisanteries à part, désolé pour commencer que vous n’ayez pas bien compris l’objectif de ce post. Cet article montre comment entrainer un modèle supervisé de ML sur la base de commentaires en utilisant du NLP « basique ».
Comme on est en mode supervisé il nous faut des notes (d’où votre étonnement peut être). Et à la fin 85% n’est que le scoring de l’entrainement, il indique quelque part la fiabilité du modèle que l’on a construit (Pour bien faire il faudrait fallu prendre de nouveaux commentaires et y appliquer le modèle).
En outre, je n’avais pas assez de données d’entrainement/test, c’est d’ailleurs pour cela que je me suis arrêté ici.
Merci en tout cas de votre remarque.
A bientot.
Merci de votre réponse. Enfin je commence à comprendre. Votre objectif est de trouver un algo capable de prévoir sur un nouveau commentaire si la note attribuée sera > ou <= à 3*
Et votre taux de 85% final c'est le taux de réussite en testant l'algo sur les mêmes données d'apprentissage. Ai-je bien compris ?
Si c'est cela c'est très intéressant mais il serait judicieux de le tester sur un échantillon totalement différent car j'ai bien peur que dans ce cas le pourcentage s'effondre
Vous avez tout compris 😉 pour bien faire il faudrait clairement un jeu d’entrainement et un jeu de test beaucoup plus conséquent. Une fois de plus l’objectif est pédagogique 😉
NB: clairement sur un autre jeu de données le score va s’effondrer.
Bonjour,
J’aimerai savoir à quoi correspond la variable X et comment vous l’avez définie svp. (dans la partie simplification des données) Merci.
Il s’agit initialement du jeu de donnees source mais X va evoluer. cf. https://github.com/datacorner/les-tutos-datacorner.fr/blob/master/string-management/sentiment-analysis/sentiment_analysis_prep.ipynb
Bonjour,
je suis entrain reprendre votre code sur l’analyse de sentiments de critiques et le code de me bloque à cette ligne là:
ValueError Traceback (most recent call last)
in
2 from sklearn.preprocessing import LabelEncoder, OneHotEncoder
3 cv = CountVectorizer(binary=True)
—-> 4 cv.fit(Xf[« Description »])
5
6 Xf_onehot = cv.transform(Xf[« Description »])
ValueError: np.nan is an invalid document, expected byte or unicode string.
Merci d’avance pour l’aide