

Décidément le monde des Pandas ne cesse de s’étoffer mais aussi d’évoluer! Avec la nouvelle librairie ydata-profiling (qui pour information s’appelait auparavant Pandas Profiling) l’analyse de données automatique est à la portée de tous. A tel point qu’il faut presque se poser la question d’utiliser un outil tiers tant la complétude des informations sur une source de données utilisée est grande. Simple et rapide à mettre en œuvre je ne pouvais pas passer à coté de ce petit bijoux du profiling.
Premier profiling
Commençons pas installer la librairie avec Python/pip :
pip install ydata-profilingComme on pourrait s’en douter cette librairie utiliser des DataFrame Pandas. Nous allons donc repartir des données du titanic pour regarder ce que cela donne.
from ydata_profiling import ProfileReport
import pandas as pd
train = pd.read_csv('../datasources/titanic/train.csv')Générons ensuite le rapport de profiling. 2 lignes de code suffisent :
prof = ProfileReport(train)
prof.to_file(output_file='rapport.html')Un fichier rapport.html est alors généré. Ce rapport complet présente toutes les informations utiles pour commencer à travailler les données.
Description des éléments analysés
Voici à quoi ressemble la page html générée :
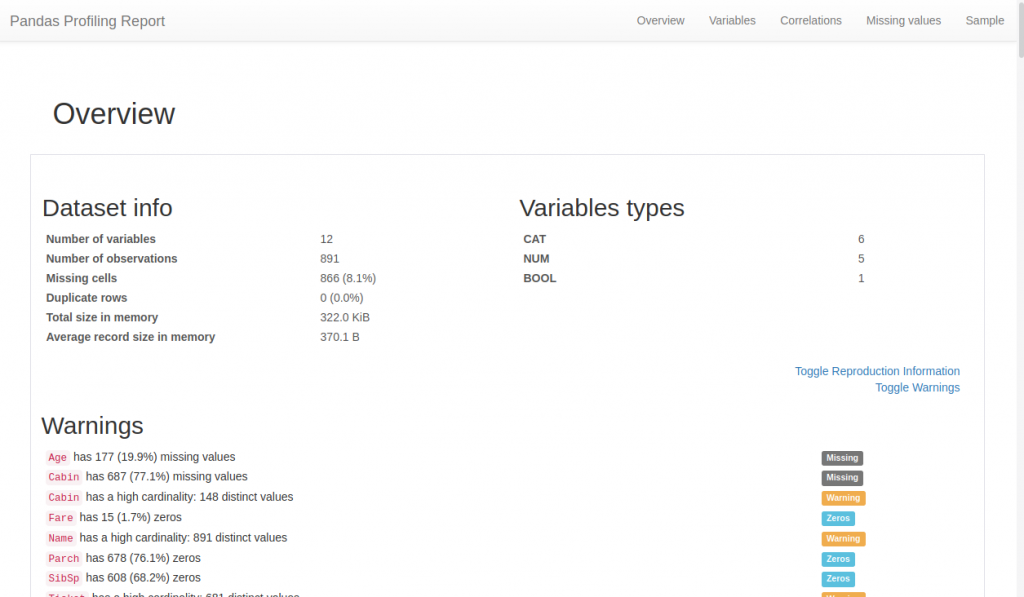
Nous y retrouvons, organisé de manière séquentielle (ou via le menu du haut) :
- Une synthèse permettant en un coup d’oeil de trouver les grand soucis à gérer pour un data scientist : données manquantes, cardinalité, etc.

- Des informations de bases comme: Le nombre de colonnes/lignes, les données manquantes ou en doublon, la mémoire occupée, etc.

- Par colonne:
- Des statistiques quantiles: valeur minimale, Q1, médiane, Q3, maximum, plage, plage interquartile
- Des Statistiques descriptives telles que la moyenne, médiane, écart-type, somme, écart absolu médian, coefficient de variation, kurtosis, asymétrie
- Inférence de type : Les types des données réelles constatés dans le jeu de données (chaînes catégorielles, numériques, etc.)
- Les Valeurs les plus fréquentes
- Distribution des valeurs (Histogrammes)

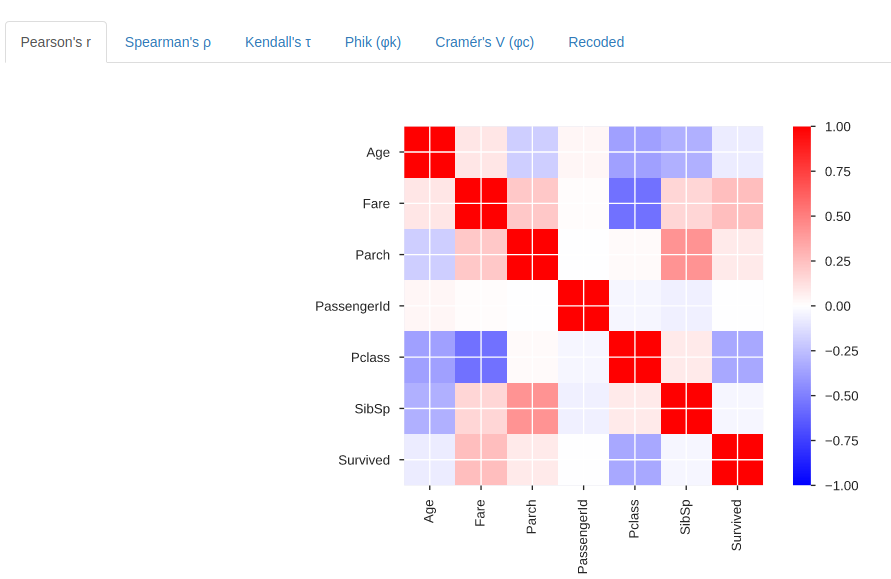
- Une analyse détaillée des corrélations mettant en évidence des variables hautement corrélées, matrices Spearman, Pearson et Kendall :
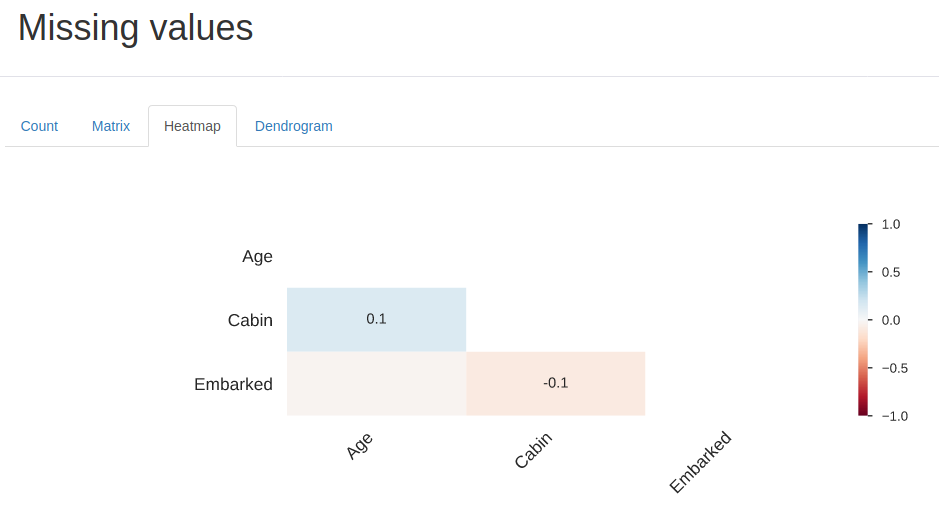
- Matrice des valeurs manquantes, comptage, carte thermique et dendrogramme des valeurs manquantes
- L’analyse de texte vous informe sur les catégories (majuscules, espace), les scripts (latin, cyrillique) et les blocs (ASCII) de données texte.
Allons un peu plus loin avec la librairie
Pour ceux qui utilisent Jupyter (comme moi) au lieu de générer un fchier html séparé on peut afficher le rapport dans un notebook :
profile = ProfileReport(train, title='Analyse du fichier Titanic', html={'style':{'full_width':True}})
profile.to_notebook_iframe()Et si on voulait traiter les données résultat dans un script ou un autre programme, on peut aussi récupérer le résultat des analyses au format JSON:
profile.to_json()Pour sauvegarder manuellement :
profile.to_file(output_file="titanic.html")Et pour les gros fichiers de données, l’analyse pourrait être vraiment très longue. Vous pouvez alors limiter l’analyse via l’option minimal. Certains traitements lourd comme les correlations ne seront pas exécutés:
profile = ProfileReport(large_dataset, minimal=True)Conclusion
Vous savez maintenant comment faire un profiling avancé sur un jeu de données sans aucun effort (bon ok juste 2 lignes de Python). Attention car comme je le précisais juste avant les traitements sous-jacents à ce profiling peuvent être très lourd … gare au gros Dataframe donc sans quoi il vous faudra vous armer de patiente.
Retrouver les éléments de cet article dans Github (cf encart ci-dessus)
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.
Merci pour ce merveilleux article sur l’utilisation de ydata-profiling pour analyser les données. J’ai trouvé votre explication très claire et informative. J’ai été particulièrement impressionné par la variété d’informations disponibles dans le rapport de profilage, notamment les statistiques quantiles, les statistiques descriptives et l’analyse des corrélations. J’ai également apprécié la possibilité d’afficher le rapport dans un notebook Jupyter ou de récupérer les résultats au format JSON pour une utilisation ultérieure. Dans l’ensemble, je pense que ydata-profiling est un outil très utile pour analyser les données et je suis reconnaissant pour votre article qui m’a permis de le découvrir.
Merci pour cet article informatif sur ydata-profiling. L’analyse automatisée des données qu’elle permet semble très complète, ce qui est très utile pour les data scientists. Les exemples de code sont également clairs et faciles à suivre. Je vais certainement essayer cette librairie pour mes prochains projets de traitement de données.