

Variable catégorielle
Savez-vous ce qu’est une variable catégorielle ? Si vous ne le savez pas vous avez certainement rencontré les soucis que ce type de caractéristiques impose par rapport aux algorithmes de Machine Learning. Pour faire simple ce type de caractéristique n’est pas quantitative (variable ordinale). Elle n’est donc pas numérique (enfin dans la majorité des cas) mais propose une information qualitative tout aussi importante.
Votre défi en tant que Data Scientiste est de convertir ce qualitatif en quantitatif !
Néanmoins la chose n’est pas aisée car pour convertir du qualitatif il faut connaitre sa valeur et pouvoir la mettre en échelle par rapport aux autres données disponibles. Une approche au cas par cas semble s’imposer, mais d’autres techniques plus simple peuvent vous permettre d’avancer.
L’encodage one-hot
C’est la méthode la plus simple. Celle que vous allez bien souvent utiliser avant toute chose. L’idée est très simple : créer et ajouter des colonnes (dummies) binaires qui réfèrent ou non la donnée par un 0 ou 1. Prenons par exemple le jeu de données titanic, vous avez des colonnes qui contiennent des variables catégorielles comme Sexe, Cabine, etc. L’idée est de rajouter des colonnes supplémentaires au jeu de données en spécifiant par rapport à chaque données si elle existe ou pas.
L’exemple du Sexe est plutôt parlant. Dans le jeu de données cette variable catégorielle prend seulement deux valeurs male et female. Nous remplacerons donc cette colonne (à deux valeurs) par deux colonnes male et female.
Vous pouvez le vérifier simplement avec la librairie Pandas comme suit :
display(titanic.columns)
cols = ['Sex', 'Embarked']
for col in cols:
display('Colonne: ' + col)
display(titanic[col].value_counts())
Note : J’y ai ajouté la variable catégorielle Embarked afin d’affiner le modèle futur.
Heureusement la librairie Pandas vient une nouvelle fois à notre secours et créé pour nous les fameuses colonnes dummies en un tour de main (grâce à la méthode get_dummies) :
data_dummies = pd.get_dummies(titanic, prefix=['S', 'E'], columns=['Sex', 'Embarked']) display(data_dummies.columns) data_dummies.head(5)
Voici le résultat :
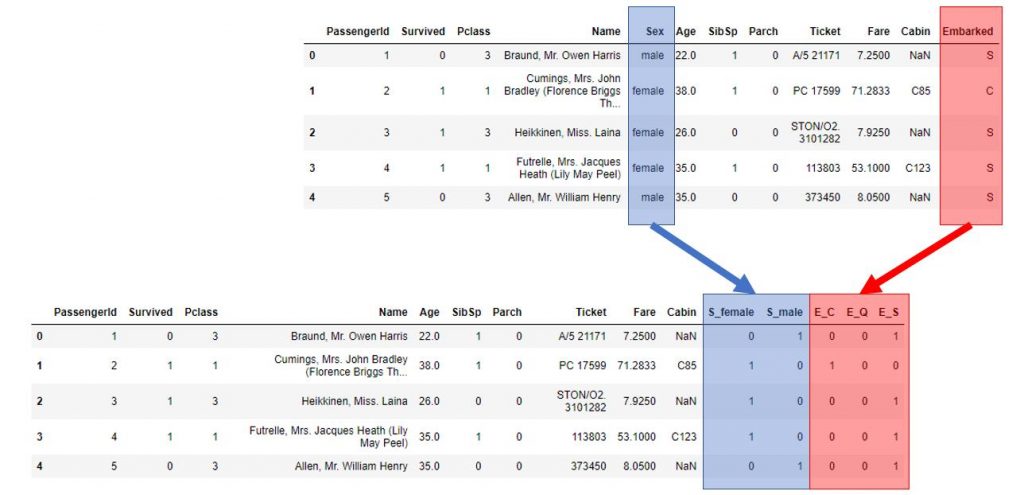
Quelques limites
Ne vous êtes-vous pas demandé pourquoi n’avoir pas prit la colonne Cabin ou même la colonne Name ? et bien tout simplement parceque ces colonnes présentent trop de valeurs sur leur distribution. En effet y ajouter des colonnes dummies risquerait d’ajouter presque autant de colonnes que de lignes exxistantes ! (c’est surtout vrai pour le nom) et donc aucun interet pour la suite des traitements.
Une solution intermédiaire va nous obliger à décortiquer les données afin de les regrouper dans des clusters plus larges. Ceci nous permettra d’y appliquer la méthode précédente.
Pour la colonne Name, pourquoi ne pas découper (parser) ce nom et y récupérer le nom de famille. La fréquence de distribution des noms de familles permettra-t-elle de créer un groupe suffisant ? Pour la colonne Cabin, pourquoi ne pas parser/récupérer la première lettre ? Il est fort probable que la première lettre corresponde à un pont du bateau par exemple, non ?
Essayons cela avec Pandas. Regardons tout d’abord la distribution de cette caractéristique :
display(titanic['Cabin'].value_counts())
Nous obtenons 147 valeurs possibles sur ce jeu d’essai.
Attention car nous avons des valeurs non renseignées (NaN), qu’il faut combler pour ce parametre, pourquoi ne par rajouter (pour l’instant un pont fictif X) ?
cabin = titanic['Cabin'].fillna('X')
display(cabin.value_counts())
Évidemment nous avons maintenant 148 valeurs distinctes.
Ne prenons maintenant que le premier caractère de la cabine :
display(cabin.str[0].value_counts())
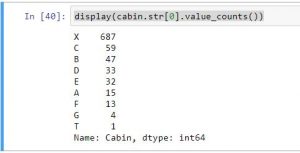
C’est bien mieux nous n’avons plus que 9 valeurs possible !
Pourquoi ne pas rajouter cette nouvelle colonne (Pont ?) et la transformer en colonnes (9) dummies maintenant ?
Un autre soucis que vous pourrez rencontrer, c’est quand votre variable catégorielle est de type numérique. Celà arrive souvent en fait et dans ce cas là scikit-learn vous propose la classe OneHotEncoder pour gérer ce cas de figure.
Appliquons notre travail avec une régression logistique
Préparons tout d’abord les données afin ne l’oublions pas de ne fournir que des données numériques à notre algorithme de régression logistique (sur les données titanic):
from sklearn.linear_model import LogisticRegression
lr1 = LogisticRegression()
def Prepare_Modele(X, cabin):
target = X.Survived
sexe = pd.get_dummies(X['Sex'], prefix='sex')
cabin = pd.get_dummies(cabin.str[0], prefix='Cabin')
age = X['Age'].fillna(X['Age'].mean())
X = X[['Pclass', 'SibSp']].join(cabin).join(sexe).join(age)
return X, target
X, y = Prepare_Modele(titanic, cabin)
lr1.fit(X, y)
lr1.score(X, y)
Nous obtenons ainsi un score de 81%
La conclusion est qu’il n’existe pas de recette miracle quant il s’agit de traiter des variables catégorielles. Bien souvent c’est ici qu’une connaissance métier s’avère indispensable afin de mieux appréhender et gérer ces caractéristiques.
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.
good
avez vous des livres publiés?
Bonjour,
Vous pourrez trouver mon dernier livre sur la data ici https://www.editions-eni.fr/livre/la-data-guide-de-survie-dans-le-monde-de-la-donnee-9782409037160