

Après avoir travaillé sur la classification binaire dans la compétition kaggle avec les données du Titanic, que diriez-vous d’aborder une autre facette du Machine Learning ? La classification multiple (Multi-classe) au travers de la reconnaissance de chiffres/digit MNSIT (Modified National Institute of Standards and Technology database) figure en effet comme un incontournable dans l’initiation au Machine Learning. Laissons-nous donc emporter dans cette nouvelle compétition Kaggle 🙂
NB: La base de données MNIST pour Modified ou Mixed National Institute of Standards and Technology, est une base de données de chiffres écrits à la main. La base MNIST est devenu un test standard. Elle regroupe 60000 images d’apprentissage et 10000 images de test, issues d’une base de données antérieure, appelée simplement NIST1. Ce sont des images en noir et blanc, normalisées centrées de 28 pixels de côté. (Source : wikipédia)
Récupérer et lire le jeu de données
Pour ce faire inscrivez-vous tout d’abord dans la compétition Kaggle, puis récupérez les données dans l’onglet data.
Voici la structure des fichiers d’entrainement et de test :

Comme d’habitude bien sur les étiquettes (label) ne sont pas présents dans le jeu de données de test … où serait l’enjeu sinon ? 😉
Nous devons traiter des images. Or ces images sont des bitmaps, c’est à dire qu’elles sont représentées via des matrices de pixels. Chaque point/pixel est donc une entrée dans la matrice. La valeur dans la matrice définissant l’intensité du point (niveau de gris) de l’image :
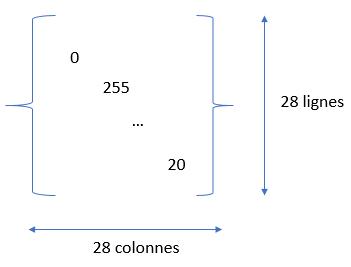
Le seul hic c’est que les données que nous récupérons ne sont pas exactement sous ce format matriciel. en fait chaque image est mise à plat sur une seule ligne. Il va donc falloir récupérer la ligne entière (sans le label bien sur) et redimensionner la ligne en une matrice 28×28. Heureusement la fonction reshape() arrive à votre rescousse, mais nous verrons cela dans le chapitre suivant.
Cette étape n’est pas nécessaire si vous ne désirez pas retoucher ou retravailler les images. Vous pourriez tout à fait lancer directement un algorithme de Machine learning sur les données matricielles en ligne :
import pandas as pd
from sklearn.linear_model import SGDClassifier
pd.options.display.max_columns = None
TRAIN = pd.read_csv("./data/train.csv", delimiter=',') #, skiprows=1)
TEST = pd.read_csv("./data/test.csv", delimiter=',') #, skiprows=1)
X_TRAIN = TRAIN.copy()
X_TEST = TEST.copy()
y = TRAIN.label
del X_TRAIN["label"]
sgd = SGDClassifier(random_state=42)
sgd.fit(X_TRAIN, y)
print ("Score Train -->", round(sgd.score(X_TRAIN, y) *100,2), " %")
Score Train --> 85.88 %Sans aucun ajustement et en quelques lignes vous aurez ainsi un score honorable de 85% (si vous le soumettez tel quel à kaggle vous obtiendrez 84% ce qui est cohérent). Mais bien sur nous pouvons faire mieux, bien mieux.
Visualiser les images
La portion de code suivant récupère une ligne du jeu de données. La ligne est convertie en une matrice 28×28 via la fonction reshape() et et visualisée via matplotlib.
# returns the image in digit (28x28)
def getImageMatriceDigit(dataset, rowIndex):
return dataset.iloc[rowIndex, 0:].values.reshape(28,28)
# returns the image matrix in one row
def getImageLineDigit(dataset, rowIndex):
return dataset.iloc[rowIndex, 0:]
imgDigitMatrice = getImageMatriceDigit(X_TRAIN, 3)
imgDigit = getImageLineDigit(X_TRAIN, 3)
plt.imshow(imgDigitMatrice, cmap=matplotlib.cm.binary, interpolation="nearest")
plt.axis("off")
plt.show()
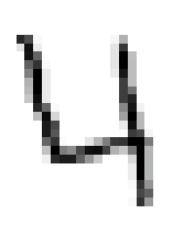
Le résultat est alors affiché :
Classification multi-classe
Dans le projet du Titanic, nous étions dans un projet de Machine Learning de type classification binaire. En effet nous devions déterminer si les passagers étaient soit survivants soit décédés. 2 possibilités seulement, d’où le terme de classification binaire. La classification multi-classe étend ce principe de classification à plusieurs classes d’étiquetage. C’est exactement le cas ici car nous devons classifier les chiffres sur les différentes possibilités [0..9].
Coté algorithmes de Machine Learning nous avons donc deux manières de gérer ce type de problèmes:
- En utilisant des algorithmes de classification binaire. Dans ce cas il faudra appliquer plusieurs fois ces algorithmes en « binarisant » les étiquettes. Par exemple en appliquant un algorithme qui reconnaitra, les 1, puis les 2, etc. C’est ce que l’on appelle une strétégie seul contre tout (One versus All). Une autre méthode consistera a confronter les couples/tuples les uns aux autres (One versus One)
- En utilisant des algorithmes Multi-classe. La librairie scikit-learn en propose un bon nombre :
- SVC (Support Vector Machine)
- Random Forest
- SGD (Stochastic Gradient Descent)
- K proches voisins (KNeighborsClassifier)
- etc.
Analyse des résultats
Dans un chapitre précédent nous avons lancé un entrainement sur les données avec une algorithme de Descente de Gradient stochastique (SGD). Nous avons vu dans un autre article comment analyser les résultats d’une classification binaire, mais quid d’une classification multi-classe ?
Et bien nous allons simplement utiliser les mêmes outils d’analyse que la classification binaire, mais bien sur manière quelque peu différentes.
L’outil le plus pratique à mon sens reste la matrice de confusion. La différence ici est nous allons la lire différemment.
sgd = SGDClassifier(random_state=42) cross_val_score (sgd, X_TRAIN, y, cv=5, scoring="accuracy") y_pred = cross_val_predict(sgd, X_TRAIN, y, cv=5) mc = confusion_matrix(y, y_pred) print(mc)
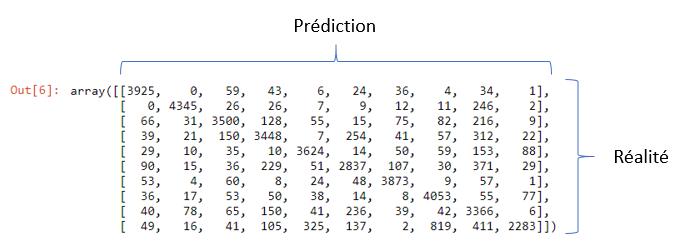
Voici le résultat :
Cette dernière est très pratique et vous permet de confronter par classe (ici je vous le rappelle [0..9]) le nombre de valeurs erronées entre la prédiction et la valeur réellement constatée. Par corollaire, une matrice de confusion étant diagonale signifie un score de 100% ! on ne va donc s’interresser qu’aux valeurs qui sont hors diagonales, car ce sont celles qui pointent les erreurs de prédiction.
Une visualisation sous forme de carte de chaleur est aussi très utile. Un simple appel à matplotlib via la méthode matshow() et le tour est joué :
plt.matshow(mc)

Premières conclusions
Dans ce premier article nous n’avons pas encore fait grand chose à vrai dire. Lire les données et lancer un premier algorithme afin de se donner un premier aperçu est indispensable et figure comme la première étape afin de se faire une idée de ce que l’on va mettre en oeuvre par la suite pour atteindre notre objectif.
Dans un second article, nous verrons en effet comment utiliser au mieux ce jeu de données. Nous pourrions par exemple retravailler les informations (en étendant par exemple le jeu de données) ou mettre à l’échelle les données matricielles. Et surtout finalement nous testerons et optimiserons nos algorithmes de machine Learning.
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.
One Reply to “MNSIT : Reconnaître les chiffres (Partie 1)”