

Introduction
Dans cet article nous allons voir comment nous allons pouvoir récupérer des informations (photo, et autres informations) à partir d’une carte d’identité scannée. L’idée est de mettre en pratique les articles précédents sur la reconnaissance faciale et la reconnaissance de texte (avec tesseract).
Voici donc la carte d’identité que nous allons analyser :

Inutile de préciser que cette carte d’identité est fictive 🙂 néanmoins nous allons retrouver les mêmes difficultés que sur une vraie. Nous utiliserons comme language Python et les librairies OpenCV et Tesseract (pour l’OCR). Les premières lignes ne doivent pas générer d’erreur sans quoi vous devrez importer les librairies (n’oubliez pas numpy, Image, etc.) via pip par exemple.
try:
from PIL import Image
except ImportError:
import Image
import pytesseract
from pytesseract import Output
import cv2
import numpy as np
from matplotlib import pyplot as pltDécoupage de la photo
Comme nous l’avons vu dans l’article sur la reconnaissance faciale, nous allons tout d’abord reconnaître et découper la photo d’identité en utilisant la reconnaissance faciale d’OpenCV.
Note : Utilisez le modèle haarcascade_frontalface_default.xml pour ce type de détection.
imagePath = r'ci.jpg'
dirCascadeFiles = r'../opencv/haarcascades_cuda/'
image = cv2.imread(imagePath)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cascadefile = dirCascadeFiles + "haarcascade_frontalface_default.xml"
classCascade = cv2.CascadeClassifier(cascadefile)
faces = classCascade.detectMultiScale(
gray,
scaleFactor=1.1,
minNeighbors=5,
minSize=(30, 30),
flags = cv2.CASCADE_SCALE_IMAGE
)
print("Il y a {0} visage(s).".format(len(faces)))
# Coordonnées des rectangles des visages détectés (x, y, w, h)
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x+w, y+h), (0, 255, 0), 2)
plt.imshow(image)
Aucune difficultés à signaler, OpenCV détecte très bien le visage et nous pouvons donc l’extraire simplement en faisant une opération de slicing avec numpy :
f = faces[0]
plt.imshow(image[f[1]:f[1]+f[3], f[0]:f[0]+f[2]])
Récupération des autres informations
L’objectif est maintenant de récupérer les informations textuelles de la carte d’identité. Essayons tesseract directement sur l’image source :
print(pytesseract.image_to_string(image))REPUBLIQUE FRANCAISE
‘CARTE NATIONALE DIDENTITE Ne 7700773MIO777__Nationaité Francaise
MS Nom! JACKSON
Prtnomiy: MICHAEL, JOSEPH
Sexe: H Nef le: 29.08, 1958
IDFRAJACKSON<<<<<<<<Nous récupérons tant bien que mal les différentes informations. Néanmoins on trouve beaucoup d’erreurs d’interpretation (Prtnomiy à la place de Prénom(s), etc.) qui risquent de rendre difficile une récupération intelligente des différents éléments. Cela est peut être dû au fond complexe de la carte d’identité (filigrammes et autres) qui rendent la tâche difficile à tesseract. Essayons re retoucher l’image (en jouant sur les seuils, niveaux de gris, etc.):
# Niveaux de gris
def grayscale(image):
return cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Réduction de bruits
def remove_noise(image):
return cv2.medianBlur(image,1)
# Seuillage
def thresholding(image):
return cv2.threshold(image, 200, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)[1]
finalimage = remove_noise(thresholding(grayscale(image)))
plt.imshow(finalimage)
texteCI = pytesseract.image_to_string(finalimage)
print(texteCI)
Le résultat est guère meilleur en réalité, nous allons donc tenter une approche différente.
Approche ciblée
La qualité de informations étant difficile à interpréter, une bonne approche consiste sans doute à cibler les informations que l’on va envoyer à tesseract. Ainsi on va découper l’image en plusieurs morceaux. Chaque morceaux devra contenir les informations à récupérer. La carte d’identité est plutôt un bon exemple car les informations sont toujours placées à peu près au même endroit.
Nous allons commencer par récupérer les coordonnées du cadre contenant le nom. Nous avons besoin du point en haut à gauche et de celui en bas à droite. le plus simple est d’ouvrir l’image dans un outil de dessin (comme pinta sur ubuntu) et de regarder les coordonnées quand on passe la souris (cf. cadre en haut à droite en rouge) :
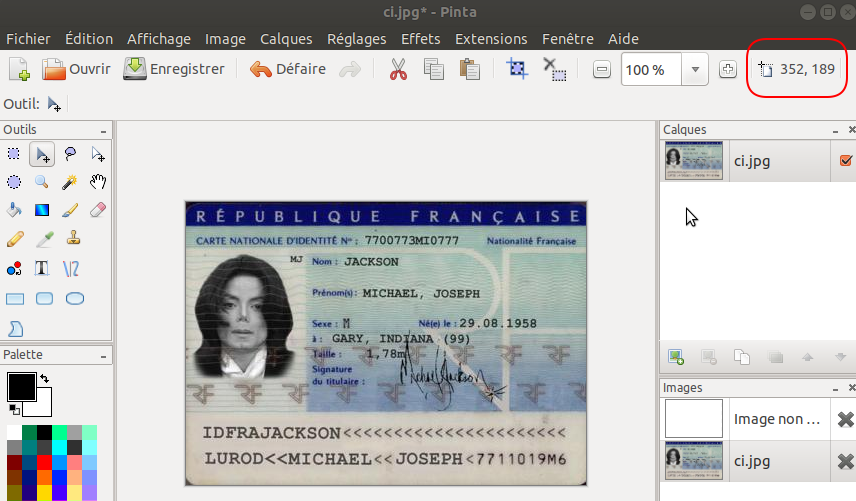
Une fois les deux points récupérés, il suffit de découper l’image via une opération de slicing avec numpy. Vérifions que le cadre d’identitication est bien le bon :
image = cv2.imread(imagePath)
x = 151
y = 49
w = 300
h = 69
plt.imshow(cv2.rectangle(image, (x, y), (w, h), (0, 255, 0), 2))
Maintenant, nous pouvons extraire l’image :
region_Nom = image[y:h, x:w]
plt.imshow(region_Nom)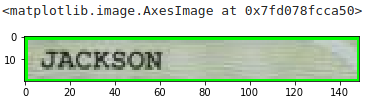
Utilisons tesseract sur cette image découpée :
region_Nom = remove_noise(thresholding(grayscale(region_Nom)))
NomCI = pytesseract.image_to_string(region_Nom)
print(NomCI)JACKSONSuite ?
Il suffit maintenant d’appliquer la même méthode sur les autres zones à récupérer. Un petit bémol tout de même, nous avons découpé l’image selon des coordonnées fixes. Le soucis est qu’il peut y avoir des décalage lors des scan des différentes cartes d’identités: ces coordonnées risquent donc de ne par être bonnes d’une image à une autre. La technique consiste donc à repérer un élément fixe sur l’image (comme par exemple le R de République Française en haut) et d’en faire le point de référence pour les coordonnées de repérage.
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.
Bonjour
je vous remercie de votre excellente travail je suis entrain de travailler sur un projet du genre pour memoire de master 2 reconnaissance d’un piece d identité et passeport pour remplir de manière intelligente un formulaire
je voulais avoir votre code source complet sur idcart
merci et sa me ferai aussi plaisir d avoir votre adresse mail
Merci à toi 🙂
Le code (entier) se trouve sur GitHub ici (section Uses cases) : https://github.com/datacorner/les-tutos-datacorner.fr/blob/master/uses-cases/id-card/Carte_identit%C3%A9.ipynb
Mon mail : benoit@datacorner.fr
Bon courage pour ton mémoire, et n’hésites pas à partager tes découvertes 😉
Benoit
MERCI
vous êtes vraiment super je vous écrit par mail
bonjour
je voulais faire une certification IA on line vous me conseiller lequel
merci
bonjour j’ai eu quelque erreur avec le code je vous envoyer un message par mail
bonjour Benoit
je travail actuellement sur la détection des MRZ des passeport et pièce d’identité j’arrive a couper la partie MRZ et récuperer les informations mais j’ai des problèmes précisions avec la confusion des M a H ET W a U
je pensais a créer un model de détection pour avoir des résultat plus nette avec l’apprentissage
mais je ne sais pas comment pouvez vous me guidez svp
merci d’avance
Bonjour, suis en année terminale de licence mais j’ai un peu un soucis. J’aime bien les machines learning précisément sur la vision par ordinateur mais le problème ce que j’arrive pas à trouver un bon sujet pour la soutenance de mon mémoire ne pourriez vous pas m’aider ?
J’ai testé tesseract ocr sur des images de plaques d’immatriculation, le résultat est tres mauvais. J’ai également testé easyocr mais je n’ai jamais reussi a le faire marcher.
Finalement j’ai reussi a faire fonctionner kerasocr avec succé sur des plaques d’immatriculation.
Je cherche à améliorer le temps nécessaire a l’analyse mais mon pc portable semble pas fonctionner avec gpu, seul le cpu travaille.
Normalement avec l’utilisation du gpu le temps nécessaire est fortement reduit.
Avez vous déja testé kerasocr?