

Flask … Qu’est-ce que c’est ?
Dans mon article précédent nous avons vu comment conserver simplement l’entraînement de d’un modèle de Machine Learning grâce à la persistance. L’objectif est maintenant de publier et d’utiliser un modèle au travers d’un programme extérieur ou mieux d’une application web.
Si vous vous orientez sur une architecture de type micro-service par exemple, il semblera logique d’utiliser des services REST. Et figurez-vous que ça tombe bien parce qu’il existe un micro-framework Python assez magique pour cela : Flask.
Pourquoi Magique ?
Tout simplement parceque Flask, contrairement à ses concurrents (Django, Pylons, Tornado, Bottle, Cherrypy, Web2Py, Web.py, etc.) est un framework d’une simplicité et d’une efficacité déconcertante. Dans cet article, je vous propose de le vérifier par vous-même.
En plus il est 100% Open-Source … alors que demander de plus ?
Petit (léger) mais costaud Flask permet l’ajout de composants additionnels mais aussi intègre un véritable moteur de template pour y associer des couches HTML/CSS. Dans cet article nous ne nous focaliserons que sur les aspects REST de ce framework et nous verrons surtout comment l’utiliser de manière pragmatique pour appeler un modèle de Machine Learning.
Installation de Flask
Travaillant sur Linux/Ubuntu vous n’aurez qu’à taper dans un shell:
sudo apt-get install python python-pip sudo apt-get install python3-flask sudo pip install flask
Pour ceux qui persistent sur windows 😉 je vous suggère d’installer Anaconda tout d’abord, puis d’installer via le navigateur (Anaconda) le module Flask.
Quant aux fans d’Apple/MAC, voici les commandes à lancer:
curl -O http://python-distribute.org/distribute_setup.py python distribute_setup.py easy_install pip pip install flask
Ce qui est vraiment génial avec Flask c’est que vous n’avez pas besoin d’installer un serveur Web. Vous allez créer un script Python qui va tout d’abord se mettre en écoute sur un port en HTTP et qui distribuera à votre code les URL. Et ce en quelques lignes de code.
Votre tout premier service
Notre premier service répondra à une requête GET et ne fera qu’afficher une chaîne de caractères.
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
return "Hello datacorner.fr !"
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0', port=8080)
Quelques explications, par ligne :
- Ligne (1) : Import/référence du module Python Flask
- Ligne (2) : Création de l’application Flask, la référence __name__ permettra ultérieurement de gérer plusieurs instances.
- Ligne (3) : Création d’une route. Une route est en quelque sorte le mapping de l’URL REST qui va être appelée avec la fonction Python.
- Ligne (5-6) : Il s’agit de la fonction appelée au travers de la route ci-dessus.
- Lignes (8-9): Lancement de Flask qui se met alors en attente
- sur le port précisé : 8080
- en mode debug (très pratique, on verra notament que ce mode permet de prendre en compte les sauvegarde au fil de l’eau et en direct).
- sur l’hôte 0.0.0.0
Sauvegardez ce fichier dans un fichier avec une extension *.py (surtout ne le nommez pas flask.py par contre auquel cas vous auriez une erreur). Dans mon cas je l’ai appelé : flask_test.py
Lancez un shell (ligne de commande) et tapez :
python flask_test.py
La commande doit préciser l’hôte et le port sur lequel Flask se met en attente :
$ python flask_test.py
* Serving Flask app "flask_test" (lazy loading)
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: on
* Running on http://0.0.0.0:8080/ (Press CTRL+C to quit)
* Restarting with stat
* Debugger is active!
* Debugger PIN: 212-625-496Ouvrez un navigateur web et tapez l’URL : http://0.0.0.0/8080, vous devez observer la réponse :
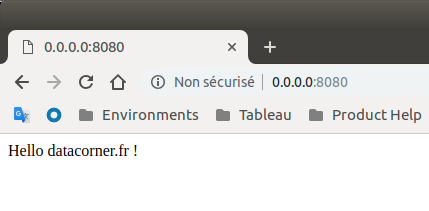
Appelez votre modèle avec Flask
Etape 1: Appel d’un modèle avec entraînement
from flask import Flask
import pandas as pd
from sklearn import linear_model
from joblib import dump, load
app = Flask(__name__)
def fitgen():
data = pd.read_csv("./data/univariate_linear_regression_dataset.csv")
X = data.col2.values.reshape(-1, 1)
y = data.col1.values.reshape(-1, 1)
regr = linear_model.LinearRegression()
regr.fit(X, y)
return regr
@app.route('/fit30/')
def fit30():
regr = fitgen()
return str(regr.predict([[30]]))
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0', port=8080)
Dans cet exemple nous créons un service REST/GET qui permet d’entraîner un modèle (celui de l’article sur la persistence des modèles de Machine Learning), et de renvoyer une valeur de prédiction sur la valeur fixe 30. Une fois la commande Python lancée votre navigateur doit afficher sur l’URL http://0.0.0.0:8080/fit30
[[22.37707681]]Etape 2 : On rend paramétrage via l’URL la valeur à prédire
Pour celà on va utiliser la possibilité de « variabiliser » les routes Flask. Pour celà on doit ajouter un paramètre dans la route (entre < et >) et ajouter le même paramètre dans la fonction. Le code devient alors :
from flask import Flask
import pandas as pd
from sklearn import linear_model
from joblib import dump, load
app = Flask(__name__)
def fitgen():
data = pd.read_csv("./data/univariate_linear_regression_dataset.csv")
X = data.col2.values.reshape(-1, 1)
y = data.col1.values.reshape(-1, 1)
regr = linear_model.LinearRegression()
regr.fit(X, y)
return regr
@app.route('/fit/')
def fit(prediction):
regr = fitgen()
return str(regr.predict([[int(prediction)]]))
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0', port=8080)
Lançons la commande Python et ouvrons un navigateur. Tapez l’URL http://0.0.0.0:8080/fit/30
Le même résultat que précédemment doit être affiché.
Etape 3 : Faisons la prédiction avec un modèle déjà entraîné
Pour celà on se référera à l’article sur la persistance des modèles de Machine learning. On va maintenant accélérer les performances en utilisant un modèle déjà entraîné :
from flask import Flask
import pandas as pd
from sklearn import linear_model
from joblib import dump, load
app = Flask(__name__)
@app.route('/predict/')
def predict(prediction):
regr = load('monpremiermodele.modele')
return str(regr.predict([[int(prediction)]]))
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0', port=8080)
Nous avons changé de route, tapez donc dans votre navigateur l’URL http://0.0.0.0:8080/fit/30 pour obtenir la même réponse que précédemment. Constatez surtout le gain de performance en changeant la valeur.
Vous voilà donc équipé pour créer des services REST qui utiliserons vos modèles de Machine Learning. Comme d’habitude les codes sources sont disponibles sur GitHub.
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.
2 Replies to “Publier vos modèles de Machine Learning avec Flask !”