

Introduction
L’idée de cet article est de montrer qu’avec quelques manipulations il est possible d’utiliser et de se faire la main sur un LLM (Large Language model).
Ces réseaux de neurones profonds (très profonds même) sont devenus courants dans ce que l’on appelle la « Gen AI » (Generative AI) et il risquent même de devenir incontournables rapidement tant les utilisations sont multiples et variées. C’est particulièrement vrai pour tout ce qui a trait au langage (NLP) avec les fameux LLM. En bref, un LLM est un type un type d’architecture de réseaux de neurones profonds qui permet de générer du texte ou comprendre le langage humain. Ces modèles sont formés sur de vastes ensembles de données textuelles, ce qui leur permet d’avoir une compréhension riche et complexe du langage. Les LLM sont largement utilisés dans diverses applications telles que la génération de texte, la traduction automatique, la réponse aux questions, et bien d’autres.
Qui d’ailleurs n’a pas entendu ou même utilisé ChatGPT ? OpenAI a en effet ouvert la voie et en montrant au monde ce dont les « Transformers » (type de réseau de neurones profond) étaient capable. L’Intelligence Artificielle est alors passé du mode fantasme au mode concrêt !
Mais que sont les Transformers ?
Je décrirais, unTransformer par une architecture de réseau de neurones conçu pour le traitement de données séquentielles utilisant ce que l’on appelle l’attention pour gérer les dépendances à long terme. Cette notion est importante car c’est ce qui permet au Transformer de gérer le contexte et donc d’être étonnamment pertinent. Ces « Transformers » sont particulièrement efficace pour le traitement de texte, la traduction et d’autres tâches liées au langage, offrant des performances élevées notamment en raison de son architecture parallèle.
Objectif
Bon j’arrête ici la théorie et je revient au cœur de cet article. Si ChatGPT a ouvert la voie (même si en réalité il n’était pas le premier de sa catégorie), beaucoup d’autres LLM sont maintenant disponibles et certains sont même Open Source, voire même gratuit (attention a bien regarder les licences) ! Ces derniers, figurez-vous prolifèrent notamment dans Hugging Face. Nous n’allons pas créer notre modèle ici mais en utiliser un (bon ok deux) qui ont déjà été construits et qui sont prêt à l’usage. La bonne nouvelle est que vous allez pouvoir tester ces LLM gratuitement puisque Hugging Face permet la création de compte sans coûts.
Note: A contrario nous n’utiliserons pas ChatGPT car l’utilisation de son modèle n’est pas gratuite. Néanmoins la transposition de tout ce qui sera fait dans cet article est très simple avec ChatGPT (pour ceux qui un compte payant chez OpenAI).
Voila donc pour les modèles que nous allons utiliser. Vous pouvez en utiliser d’autres tant Hugging Face en propose …
Maintenant il est temps de voir comment nous allons communiquer avec ces LLM. Une librairie s’est imposée naturellement sur le marché : LangChain, et pour cause elle permet très simplement d’interagir avec nos fameux LLM de manière simple et naturelle. Nous utiliserons quelques unes de ces capacités dans cet article.
Créer un compte et un token dans Hugging Face
Avant toute chose il est indispensable de créer un compte dans Hugging Face. Comme je vous l’ai dit plus haut cette création est totalement gratuite et s’effectue en quelques clics.
Une fois votre compte créé, voici les différentes étapes:
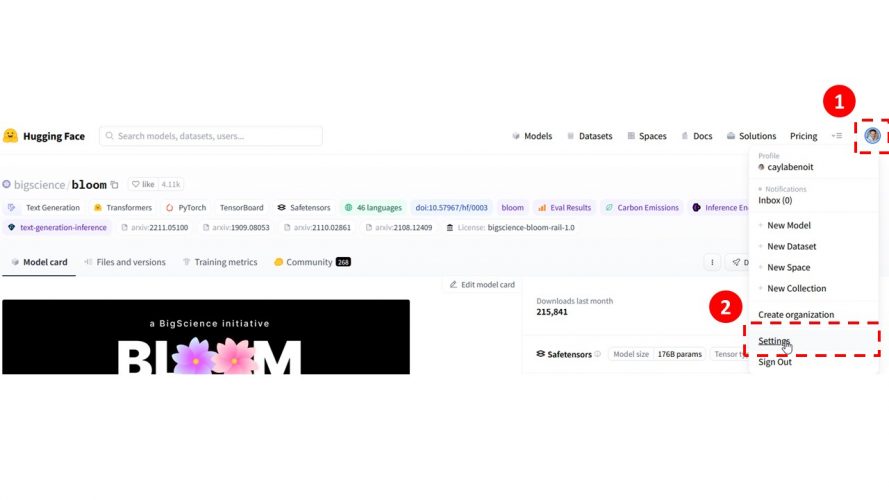
- Cliquez sur l’icône en haut à droite (votre utilisateur)
- Sélectionnez Settings
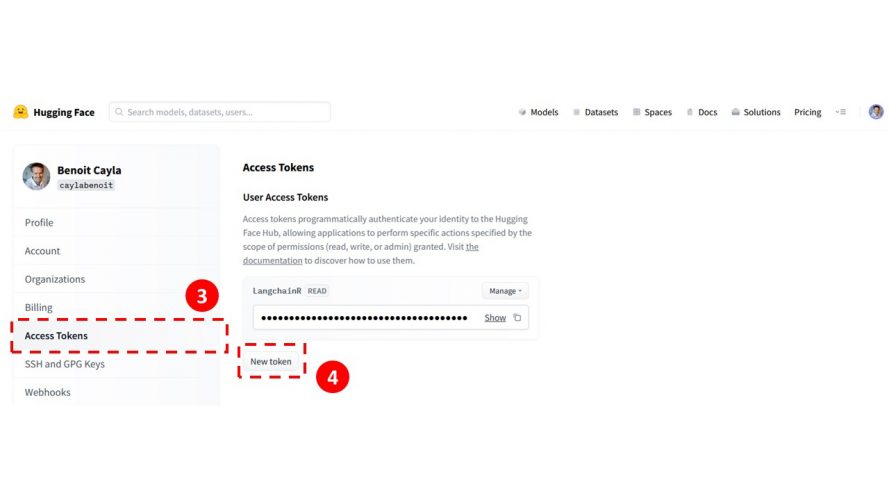
- Dans le menu de gauche, choisissez Access Token
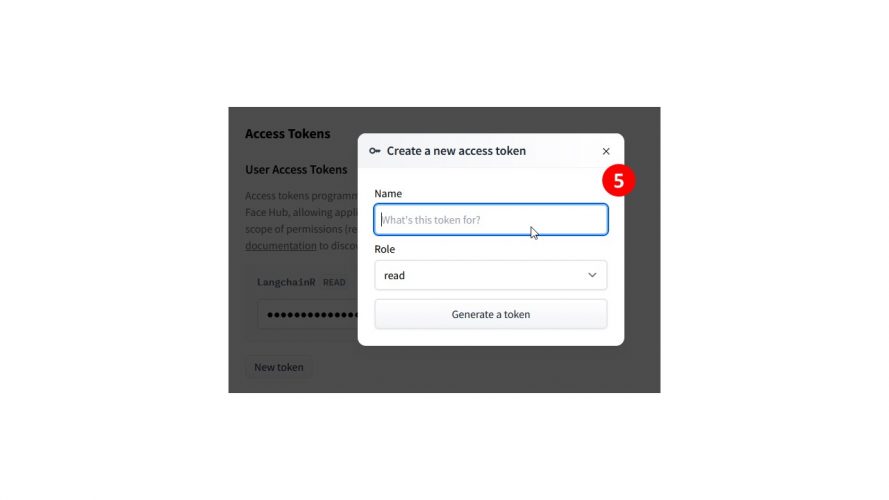
- Créez un token en cliquant sur le bouton
- précisez un nom pour vous en souvenir et une fois validé gardez le token sous la main 😉
Création du Notebook colab
Nous allons maintenant créer un notebook dans colab et surtout l’initialiser avec toutes les librairies dont il a besoin (le notebook contenant tous ce qui va suivre est aussi disponible ici). L’utilisation de Google colab permet de ne rien installer localement, mais bien sur il est possible d’utiliser Python directement sur votre machine.
Tout d’abord il faut installer les package LangChain et Hugging Face:
!pip install langchain
!pip install huggingface_hubPuis on importe les librairies:
import os
from langchain import PromptTemplate, HuggingFaceHub, LLMChain
import warnings
import requestsPour éviter de répéter du code on créé 2 variables qui seront utiles tout le long et qui vont stocker les informations d’authentification:
os.environ["HUGGINGFACEHUB_API_TOKEN"] = MYHFKEY
headers = {"Authorization": "Bearer " + MYHFKEY}Note: La variable MYHFKEY contient le token Hugging Face que l’on a créé dans la section précédente.
Premier essai avec BLOOM
Nous allons tester un premier modèle (stocké par Hugging Face) BLOOM. BLOOM est un LLM (auto-régressif) formé sur de vastes données textuelles. Il génère un texte humainement convaincant dans 46 langues et 13 langages de programmation, tout en étant capable d’accomplir des tâches de génération de texte non spécifiques à son entraînement initial.
Son nom de code dans Hugging Face (repo_id) est : bigscience/bloom
Commençons par créer un prompt (une question précisément) très simple avec LangChain, juste pour lui demander comment il va:
template = """ {question}"""
prompt_template = PromptTemplate(input_variables=["question"], template=template)
prompt_template.format(question = "Comment allez-vous ?")Comment allez-vous ?LangChain fonctionne très simplement avec des templates et permet de construire des prompts dynamiques de manière efficace. Ici nous avons créé un prompt de type question, nous n’aurons qu’a changé ce paramètre (la question) pour solliciter notre LLM. Allons-y
llm=HuggingFaceHub(repo_id="bigscience/bloom",
model_kwargs={"temperature":1e-10})
chain = LLMChain(llm=llm,
prompt=prompt_template)
chain.run("Quel est le plus gros animal terrestre ?")Le plus gros animal terrestre est la baleine bleue. Elle peut mesurer jusqu'à 33 mètres de longEt voilà ! Félicitations … vous venez, en quelques lignes de code Python, d’interroger un LLM juste en lui posant une question 🙂
Utiliser les APIs via Hugging Face
Il est aussi possible d’utiliser les APIs fournies par Hugging Face pour communiquer avec le LLM. Pour celà il suffit de retourner dans Hugging Face et de cliquer sur le bouton Deploy, puis Inference API:
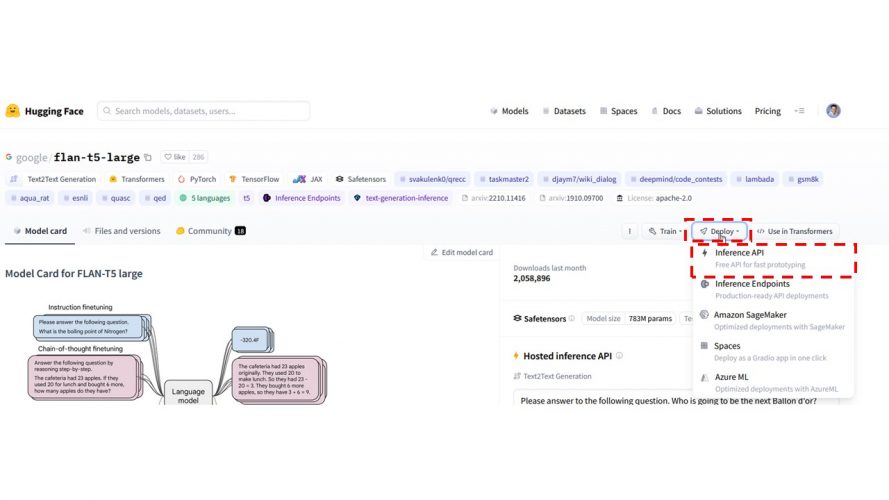
Ensuite un snipet de code est proposé, il suffit de le copier et l’adapter:
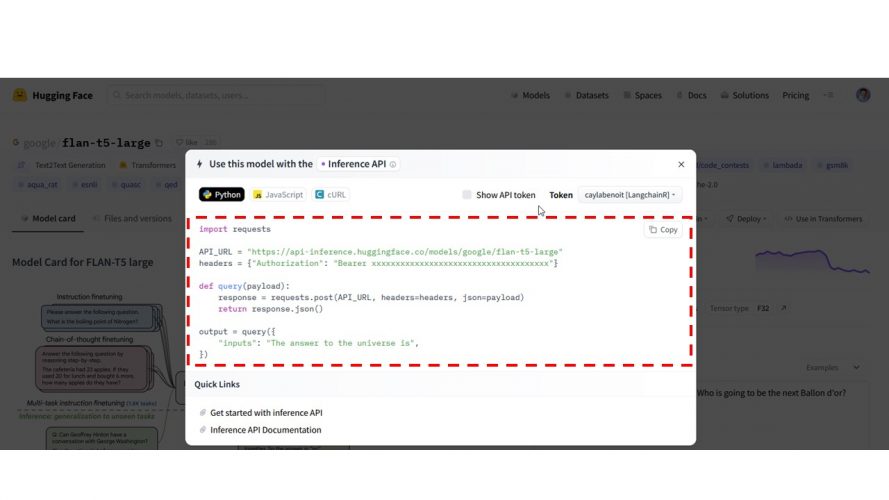
C’est ce que nous allons faire dans notre Notebook colab:
API_URL = "https://api-inference.huggingface.co/models/bigscience/bloom"
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query({
"inputs": "Le plus grand pays au monde est ",
})
print(output)[{'generated_text': 'Le plus grand pays au monde est la Russie.\nLa Russie est un pays immense.\nLa Russie est un pays immense.'}]Utilisons Google FLAN-T5
Nous allons maintenant tester tout cela avec un autre LLM : google/flan-t5-large
FLAN-T5 de Google est une version multilingue de son modèle T5, conçu pour traiter diverses langues dans les tâches de traitement du langage naturel. Il est formé sur des ensembles de données multilingues, ce qui lui permet de fournir des performances solides pour la traduction, la génération de texte et la compréhension de texte dans plusieurs langues. Pour plus de détails récents, veuillez consulter les publications et ressources de Google.
Pour utiliser un autre modèle, c’est très simple il suffit de modifier le parametre repo_id (qui correspond au nom du modèle dans Hugging Face), comme suit :
llm=HuggingFaceHub(repo_id="google/flan-t5-large",
model_kwargs={"temperature":1e-10})
chain = LLMChain(llm=llm,
prompt=prompt_template)
chain.run("quelle est la capitale de la France ?")parisDe la même manière on pourra utiliser l’API:
API_URL = "https://api-inference.huggingface.co/models/google/flan-t5-large"
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query({
"inputs": "quelle est la capitale de la France ?",
})
output[{'generated_text': 'paris'}]Conclusion
Comme je vous l’avais précisé en introduction l’idée de cet article est de montrer comment grâce à des solutions comme Hugging Face et des frameworks comme Lang Chain il est simple et rapide d’utiliser des LLM qui ont été déjà préalablement entrainés. En effet quand on veut s’exerce sur des LLM on pense tout de suite à ChatGPT ou BARD mais l’accès payant de ChatGPT peut s’avérer bloquant, notamment si on ne veut juste que se faire la main sur des outils comme Lang Chain. De plus ces LLM évoluent constament et la compétition est rude dans le monde de l’IA, d’où l’importance d’avoir accès à une certaine flexibilité. Dorénavant vous avez les outils en main pour essayer, modifier et établir des stratégies de prompt !
Ingénieur en informatique avec plus de 20 ans d’expérience dans la gestion et l’utilisation de données, Benoit CAYLA a mis son expertise au profit de projets très variés tels que l’intégration, la gouvernance, l’analyse, l’IA, la mise en place de MDM ou de solution PIM pour le compte de diverses entreprises spécialisées dans la donnée (dont IBM, Informatica et Tableau). Ces riches expériences l’ont naturellement conduit à intervenir dans des projets de plus grande envergure autour de la gestion et de la valorisation des données, et ce principalement dans des secteurs d’activités tels que l’industrie, la grande distribution, l’assurance et la finance. Également, passionné d’IA (Machine Learning, NLP et Deep Learning), l’auteur a rejoint Blue Prism en 2019 et travaille aujourd’hui en tant qu’expert data/IA et processus. Son sens pédagogique ainsi que son expertise l’ont aussi amené à animer un blog en français (datacorner.fr) ayant pour but de montrer comment comprendre, analyser et utiliser ses données le plus simplement possible.