
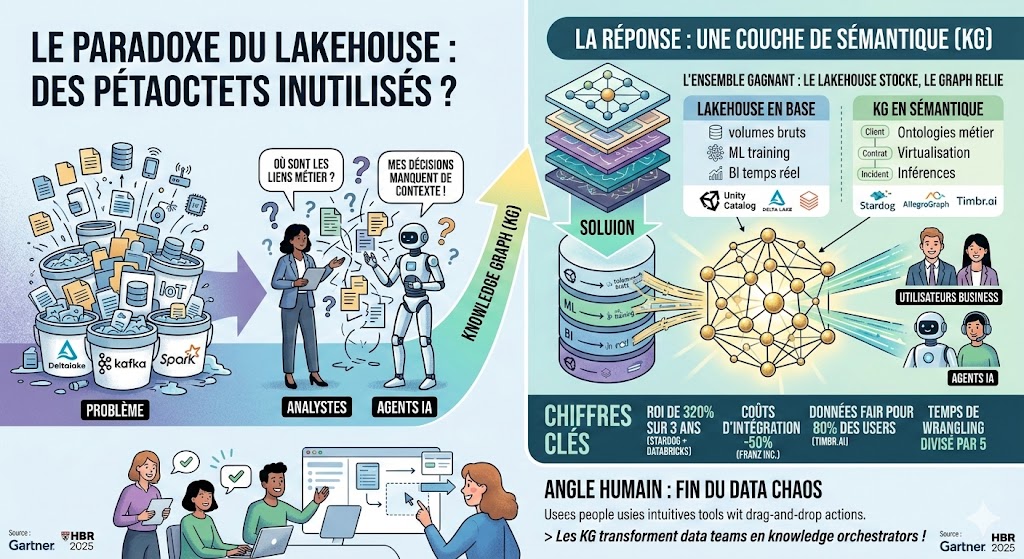
Paradoxe : Des pétaoctets inutilisés ?
Le lakehouse (le meilleur du datawarehouse et du data lake) déborde clairement de données fraîches, traitées en temps réel via Spark ou Delta Lake (Iceberg c’est bon aussi). Et pourtant, des agents IA hallucinent sur des faits basiques, les analystes passent alors des semaines à relier les silos CRM, ERP et IoT, et malgré tout des décisions stratégiques manquent de précision car elle n’ont pas le bon contexte métier. C’est un constant classique et force est de constater que le lakehouse excelle en scalabilité brute, mais il peine – seul – à donner du sens aux données. On peut voire cela comme le talon d’Achille de l’IA en entreprise aujourd’hui, du moins ce qui peut freiner son développement.
Et si la réponse était une couche knowledge graph (KG) par-dessus ?
Le problème : Scalable mais aveugle
Comme je le disais un peu plus haut, le lakehouse unifie clairement et sainement les meilleurs du data warehouse et du data lake pour des workloads analytics/ML, et … à bas coût. Mais voila, les données stockées restent souvent “plates” : tables SQL, fichiers Parquet. En gros, toutes ses informations sont stockées avec plus ou moins de relations (techniques) mais restent presque toujours sans relations métier explicites (je ne parle pas de relations physiques entre tables ici hein). Résultat ? L’IA générative (LLM, agents) bute sur le manque de sémantique – Gartner prédit d’ailleurs que 30% des projets GenAI seront abandonnés d’ici fin 2025 à cause de la mauvaise qualité data
Soyons clairs il ne s’agit pas toujours de problèmes de qualité de données (qui pourtant sont encore bien souvent trop présents), mais bien de données qui sont trop souvent hors contexte. Prenons des exemples concrets : un risk manager ne relie pas incidents fournisseurs à contrats en cours ; un marketeur ignore les interactions client multi-canaux pour personnaliser, et on peut en citer pleins comme ça !
Chiffres clés : ROI explosif prouvé
Superposer un Knowledge Graph (ou graphe de connaissances) sur un lakehouse booste peut en effet l’efficacité avec un facteur de l’oredre de la dizaine. Cf. Stardog + Databricks rapporte un ROI de 320% sur 3 ans (9,86 M$ de gains). Et tout cela avec des applications data 3x plus rapides grâce à une couche sémantique virtualisée – et sans dupliquer les données. Cela parait magique bien sur mais ce n’est ni plus ni moins que du bon sens, car utiliser la bonne données au bon moment et avec le bon contexte change totalement la donne.
Franz Inc. (AllegroGraph) le confirme d’ailleurs, le Knowledge Graph combiné au lakehouse peut réduire les coûts d’intégration de moitié et accélèrer la production d’insights avec l’IA, en connectant les entités/événements temporels et en fournissant un analytique ciblé et qui plus est performant Franz – Knowledge Graphs and AI for your Data Lakehouse.
Timbr.ai (un autre grand acteur dans cette cours de jeux) ajoute que cette stack rend les données FAIR pour 80% des users business Timbr.ai Lakehouse Semantic Model.
Complémentarité : Le lakehouse stocke, le graph relie
Puisqu’il s’agit de complémentarité, voici comment on peut voir la répartition des rôles:
Lakehouse en fondation indispensable
Le lakehouse excelle dans l’ingestion massive de données brutes, en batch ou streaming via Kafka/Delta Lake, pour gérer des pétaoctets sans friction. Il assure aussi et surtout (c’est indispensable!)
- Une gouvernance indispensable (par exemple avec Unity Catalog)
- Des requêtes SQL/ML scalables sur Spark
- Il supporte le ML ou la BI temps réel Bref c’est parfait pour volumes hétérogènes, mais reste encore limité aux schémas statiques sans inférences dynamiques Cf. Using Knowledge Graphs with Databricks.
KG en sémantique
Le knowledge graph lui apporte les ontologies métier pour modéliser relations riches (ex. : client → souscrit → contrat → lié à → incident fournisseur), avec de la virtualisation (SPARQL traduit en SQL pushdown sur lakehouse) et inférences automatiques (risques prédits, patterns cachés) pour éviter la copie de données.
Exemple concret : Utiliser une solution telle que Stardog sur Databricks (qui fédère Delta Lake + sources externes) sans duplication physique, pour alimenter un GraphRAG, des agents IA ou faire des recherches sémantiques ultra-précises.
L’ensemble gagnant
Le Knowledge Graph (KG) “active” le lakehouse fonctionnel/métier avec de requêtes cross-domain fluides (customer 360 unifié, supply chain résiliente, R&D optimisée), des LLM contextualisés sans hallucinations, et propose un ROI accéléré grâce à la couche sémantique. Pour info, des solutions telles que databricks intègrent nativement cette “couche sémantique” dans Unity Catalog pour AI/BI Genie.
Angle humain : Fin du data chaos
Disons le clairement, les data engineers adorent scaler, mais soyons tout aussi clair: les métiers veulent des réponses, pas des ETL !
Le Knowledge Graph démocratise cette approche en permettant aux analystes de faire du drag-and-drop d’ontologies dans des outils comme Stardog Designer et publient vers leur outil de BI préféré sans coder en SPARQL (bien sur).
Résultat ? Le temps de wrangling est divisé par 5, les erreurs humaines tolérées vs IA sont 10x plus fiable avec des graphes.
Les KG transforment data teams en knowledge orchestrators !
Et vous, avez-vous testé KG sur votre lakehouse ?